Cortex: Construir um Segundo Cérebro com Claude Code e Obsidian
Um sistema autónomo de gestão do conhecimento construído sobre skills, agentes e um scheduler de heartbeat

O Que é um Segundo Cérebro?
O termo foi popularizado por Tiago Forte em Building a Second Brain: a ideia é delegar o trabalho de memorizar, relacionar e recuperar informação a um sistema externo, para que o cérebro biológico possa concentrar-se em pensar em vez de armazenar.
Na prática, isto significa manter uma coleção estruturada e pesquisável de notas, registos de reuniões, planos de projeto, ideias e referências — tudo num só lugar e consistentemente organizado. O framework mais comum é o PARA: Projetos (trabalho ativo e com prazo), Áreas (responsabilidades contínuas), Recursos (material de referência) e Arquivos (itens concluídos ou inativos). O Obsidian é uma das ferramentas mais populares para o implementar, porque armazena tudo como ficheiros markdown simples que pertencem totalmente ao utilizador, liga notas de forma bidirecional e funciona sem ligação à internet.
A promessa é apelativa: décadas de conhecimento acessíveis instantaneamente, com ligações a surgir entre domínios que já tínhamos esquecido estarem relacionados. A realidade, para a maior parte das pessoas, é uma caixa de entrada com 300 notas por organizar e uma culpa crescente. O sistema não se mantém sozinho.
O Problema
Uso o Obsidian como segundo cérebro há mais de um ano. Como a maioria dos trabalhadores do conhecimento, comecei com boas intenções: capturar tudo, ligar ideias, rever regularmente. A realidade foi diferente. As notas acumulavam-se na caixa de entrada, as revisões diárias não aconteciam, e as ligações entre ideias permaneciam invisíveis.
Esse ano foi também invulgarmente atribulado. De dia, sou designer de circuitos integrados analógicos; ao longo de 2024 e 2025 estive a tirar um MBA Executivo duplo (Porto Business School e Kozminski University, concluído no início de 2026), para além da vida familiar e de alguns projetos paralelos. A captura espalhou-se por aplicações de notas, mensagens de voz e três gestores de tarefas diferentes. A síntese raramente acontecia. O segundo cérebro tornou-se mais uma coisa para alimentar em vez daquilo que organizava tudo o resto.
A fricção não estava na ferramenta. Estava na manutenção. Um segundo cérebro só funciona se o alimentarmos, podarmos e percorrermos regularmente. É exatamente o tipo de trabalho repetitivo e estruturado que um agente de IA consegue tratar.
O Que é o Cortex
O Cortex é o meu vault Obsidian, gerido pelo Claude Code através de um sistema de skills (fluxos de trabalho reutilizáveis), agentes (raciocínio especializado) e integrações (calendário, tarefas, email, monitorização de atividade física). Funciona a partir do terminal, do Telegram (com voz e TTS), por email, e de forma autónoma segundo um calendário via unidades systemd de utilizador no Linux.
O vault segue o PARA como base, adaptado com uma camada explícita de revisão temporal por cima:
0-Inbox/ → Zona de captura
1-Projects/ → Trabalho ativo e com prazo
2-Areas/ → Responsabilidades contínuas (saúde, família, carreira)
3-Resources/ → Material de referência, tópicos de interesse
4-Archives/ → Itens concluídos ou inativos
Daily/ → Notas diárias (YYYY-MM-DD.md)
Weekly/ → Notas semanais (YYYY-WNN.md) — sintetizadas a partir das diárias
Quarterly/ → Notas trimestrais (YYYY-QN.md) — objetivos, quests, revisão
Yearly/ → Notas anuais (YYYY.md) — temas anuais e retrospetiva
MOCs/ → Maps of Content para conjuntos de tópicos
Templates/ → Modelos de notas
A camada de revisão temporal é onde o sistema se justifica. Cada nível é sintetizado a partir do nível abaixo: /closeday escreve a nota diária, /closeweek parte das notas diárias da semana, /closequarter parte das semanas, e assim por diante. Sem copiar e colar manualmente; a cadência decorre de forma autónoma.
O que o distingue de uma configuração Obsidian padrão é a camada de governação: o Claude Code segue regras estritas sobre onde as notas podem ser criadas, como estão estruturadas e quando podem ser movidas. O novo conteúdo entra sempre na Inbox. Só o utilizador decide onde fica.
Arte Anterior: OpenClaw, NanoClaw e o Problema dos Custos
Antes de construir o Cortex, explorei o OpenClaw — o gateway auto-alojado mais popular para ligar aplicações de chat a modelos de IA. O OpenClaw é impressionante em âmbito: liga WhatsApp, Telegram, Slack, iMessage e mais de uma dúzia de outras plataformas a qualquer LLM, e dá ao modelo acesso a ficheiros, calendário, email e browser.
Na prática, deparei-me com três problemas.
Transparência. O OpenClaw orquestra muito nos bastidores. Não conseguia acompanhar facilmente o que o agente estava a fazer em cada passo, o que tornava a depuração difícil e a confiança mais difícil de construir. Quando algo não funcionava, a superfície de falha era grande.
Compatibilidade com modelos. O projeto afirma suporte para qualquer LLM, mas na prática os resultados com modelos que não o Claude eram inconsistentes para qualquer coisa além de consultas simples. Quanto mais complexo o fluxo de trabalho, mais se desintegrava.
Custo. Usá-lo com Claude a preços de API é proibitivamente caro para o padrão de uso diário que eu precisava: resumo matinal, captura de registo em tempo real ao longo do dia, importação de reuniões, síntese ao final do dia. Cada interação faturada por token acumula-se rapidamente a essa frequência.
O NanoClaw resolveu o problema dos custos diretamente. Funciona sobre o Anthropic Claude Agent SDK, o que significa que trabalha com uma subscrição Claude Code (Claude Max) em vez de faturação por token via API. Isso muda completamente a economia. Com custo fixo de subscrição, a sobrecarga por interação desaparece. O NanoClaw é também significativamente mais leve do que o OpenClaw (cerca de 500 linhas de TypeScript), mais fácil de compreender e construído para isolamento em contentor.
O Cortex tomou a abordagem do NanoClaw como ponto de partida e inverteu a arquitetura. A distinção mais profunda é conceptual. O OpenClaw e o NanoClaw são centrados em infraestrutura: um gateway de mensagens que liga canais de chat a um modelo, com ficheiros, calendário e email como funcionalidades acrescentadas ao gateway. O Cortex é centrado na informação: um vault Obsidian é a base (o verdadeiro segundo cérebro), e tudo o resto (bot Telegram, bot de email, agentes, schedulers, integrações) é infraestrutura construída em torno do vault. O vault é o centro de gravidade e o Claude Code é o motor. O bot Telegram e o bot de email são canais de captura que alimentam o vault, não o contrário. A subscrição Claude Code torna a economia viável ao nível de utilização que o Cortex exige.
Dois outros projetos merecem ser estudados se quiser ir mais longe. O claude-obsidian de Daniel Agrici segue um ângulo diferente: organização automática do conhecimento baseada no padrão LLM Wiki de Andrej Karpathy, sem arquivamento manual, suporte multi-modelo. É uma boa referência para o lado do grafo de conhecimento e ingestão do problema. O guia do MindStudio sobre construir um segundo cérebro com Claude Code e Obsidian cobre os fundamentos com clareza, incluindo a estrutura do CLAUDE.md e padrões de continuidade de sessão. Um bom ponto de partida para quem chega a isto pela primeira vez.
O ponto mais importante: nenhum destes sistemas deve ser copiado na íntegra. O valor de um segundo cérebro está em refletir como você pensa, no que você trabalha e no que você precisa de lembrar. O OpenClaw, o NanoClaw, o claude-obsidian e o Cortex são todos pontos de partida. O sistema que funciona é aquele que cresceu organicamente a partir das suas próprias frustrações, dos seus próprios fluxos de trabalho e do seu próprio sentido do que vale a pena automatizar. Comece com a coisa mais pequena possível que o ajude hoje. Acrescente a camada seguinte quando sentir a fricção.
O Sistema de Skills
As skills são o núcleo do Cortex. Cada skill é um ficheiro markdown (.claude/skills/<name>/SKILL.md) que define um fluxo de trabalho com múltiplas fases que o Claude Code executa quando invocado com /<name>. São prompts estruturados com injeção dinâmica de contexto.
O Cortex tem atualmente mais de 40 skills em várias categorias.
Ciclo de Vida Diário
Três skills gerem o ritmo diário:
/today — Resumo matinal: reúne contexto em paralelo (calendário em todas as contas, tarefas do Todoist, atividades do Strava, alterações no vault), destaca as prioridades e riscos do dia, escreve uma nota diária com uma Lista Fechada e uma citação.
/closeday — Síntese de fim do dia (11 fases): reúne todos os dados em paralelo, funde as notas de eventos do calendário no Live Log, escreve um snapshot Done congelado a partir das conclusões do Todoist, compõe a síntese completa (o que avançou, o que ficou bloqueado, o que surpreendeu; vitórias; reuniões; padrão rotativo dos últimos 7 dias), importa notas de reuniões do Granola, atualiza as secções de saúde e princípios, escreve a passagem de testemunho para amanhã e finaliza o Live Log. Corre de forma autónoma às 23:45 via o scheduler de heartbeat.
/wrapup — Memória de sessão: analisa o que mudou, extrai padrões duradouros, acrescenta uma linha ao Live Log. Não toca no git.
A nota diária segue uma estrutura de nove secções: Journal, Executive Summary, Health, Principles, Daily Brief, End-of-Day Synthesis, Done, Tomorrow’s Handoff, Live Log. Cada secção é preenchida por uma skill específica ou por uma ação do utilizador; nada fica em branco no final do dia.
Live Log e Captura Automática
Ao longo do dia, sinais fluem para uma secção ## 📡 Live Log na nota diária. Quatro skills leves tratam da captura explícita:
/log <texto>— sinal geral/focus <label>— marca o início de uma sessão de trabalho profundo/block <texto>— regista uma interrupção ou constrangimento externo/energy <1-5>— verificação rápida de energia (escreve no frontmatter)
O mecanismo mais interessante é a captura automática via Telegram. O bot executa um classificador em cada mensagem de forma livre:
- SKIP — confirmações curtas, instruções de tarefas, perguntas puras: não fazer nada, apenas responder
- LOG — um facto concreto (nome, número, data, decisão): acrescentar ao Live Log via
live-log.py - SEED-NOTE — novo conteúdo substancial que merece uma nota própria: criar em
0-Inbox/
As mensagens de voz são transcritas via Whisper, classificadas e registadas literalmente — preservando a voz e a língua do utilizador. O objetivo são 2 a 5 entradas no Live Log por dia; mais de 10 sinaliza deriva na narração.
Fluxos de Trabalho HITL
Várias skills são concebidas como sessões interativas em que o utilizador permanece no ciclo:
/sweep— Triagem da Inbox do Todoist: classifica cada item em projetos por horizonte temporal, propõe uma tabela diff, confirma antes de aplicar/week— Planeamento semanal: reúne contexto (Todoist, calendário, nota de fecho anterior, projetos ativos), faz perguntas estruturadas, propõe alterações no Todoist, confirma antes de escrever. O estado persiste num ficheiro JSON para que a conversa possa durar horas./quarter— O mesmo contrato ao horizonte trimestral/closeday— Lê também a entrada HITL do fim da tarde (energia, vitórias, brain_dump) a partir de um ficheiro JSON que o bot preenche à medida que as mensagens chegam entre as 20:00 e as 23:45
O contrato HITL é claro: a conversa mantém-se no canal em que começou. Pelo Telegram, a interação é pelo Telegram. Pela CLI, é pelo terminal. As skills nunca fixam um canal de saída específico.
Manutenção do Vault
/vault-status— Diagnóstico instantâneo: notas órfãs, ligações quebradas, seeds obsoletas, notas demasiado extensas, backlog da inbox/mature— Sumarização progressiva: seleciona 3 a 5 notas seed obsoletas e orienta a revisão em camadas (destacar passagens chave a negrito, realçar insights, escrever sumário destilado, promover a evergreen)/reindex— Reconstrói um índice SQLite do vault para consultas rápidas de metadados/audit-knowledge— Duplicados semânticos, clusters de tópicos sem MOC, decaimento de ligações/dream— Consolidação de memória: passagem reflexiva sobre a atividade recente para sintetizar padrões duradouros
A Arquitetura Multi-Agente
O Cortex é construído sobre um modelo multi-agente de três fases, implementado como ciclos concêntricos a correr em escalas de tempo diferentes.
Fase 1 — Sinais de deriva (a cada 15 min): Um script de heartbeat avalia três condições baseadas em regras — tarefas em atraso, backlog de email e silêncio — e envia um alerta pelo Telegram apenas quando o conjunto de sinais disparados muda em relação ao último tick. Sem tempestade de alertas, sem ruído.
Fase 2 — Raciocínio (a cada N ticks): O heartbeat lança uma sessão Claude /heartbeat-agent para raciocínio sobre deriva além do que as regras conseguem exprimir. É aqui que “não tocou em q-platform há 3 dias e a semana está quase a acabar” surge como um lembrete em linguagem natural.
Fase 3 — Agentes de domínio: Agentes autónomos especializados que correm segundo o seu próprio calendário e comunicam via um broker NATS local com JetStream. O primeiro agente em produção é o Health Agent.
O Health Agent corre de hora a hora, puxa dados de composição corporal do Withings e de treino do Strava, publica um snapshot em cortex.health.snapshot, e lança uma sessão Claude apenas quando um gatilho dispara pela primeira vez — weight_trending_up, training_gap, water_deficit, deriva de gordura corporal. A sessão Claude recebe o payload do gatilho via uma variável de ambiente e decide o que fazer com ele. O avaliador é simples e determinístico; todo o raciocínio vive no Claude.
As três fases correm sob um único cortex-heartbeat.timer (para as Fases 1-2) e cortex-health-agent.timer (para a Fase 3). O broker NATS permite que futuros agentes se subscrevam ao stream de saúde ou publiquem o seu próprio, sem reimplementar as recolhas de dados.
Nove agentes especializados estão disponíveis para as skills:
| Agente | Propósito |
|---|---|
vault-explorer | Análise profunda de padrões no vault, rastreamento de ligações |
vault-organizer | Criação de notas, organização da inbox, aplicação de modelos |
book-summarizer | Leitura de livros completos via RAG, produz notas de síntese |
Explore | Exploração de código e ficheiros, pesquisa por palavra-chave |
general-purpose | Investigação em vários passos, tarefas de código, explorações abertas |
Plan | Planeamento de implementação, decisões de arquitetura |
research-analyst | Investigação multi-fonte com síntese e identificação de tendências |
search-specialist | Recuperação precisa de informação em múltiplas fontes |
statusline-setup | Tarefas de configuração e definições |
O princípio de design mantém-se: as tarefas de síntese ficam com o modelo mais capaz, as tarefas de correspondência de padrões ficam com o modelo rápido, e a organização de rotina herda da sessão pai.
Sessões Paralelas e Sincronização Noturna
O Cortex corre regularmente 3 a 5 sessões Claude Code em simultâneo: CLI, bot Telegram, bot de email, agente de heartbeat, agente de saúde. Todas partilham o mesmo ramo main e a mesma árvore de trabalho.
A doutrina: sem commits durante o dia. Todas as sessões editam ficheiros livremente ao longo do dia. Uma única tarefa noturna (cortex-vault-sync.timer, às 02:00) para todos os serviços escritores, executa git add -A, faz commit com o assunto nightly sync: YYYY-MM-DD, faz push e reinicia tudo.
Isto elimina a dor das colisões de commits que afligia o modelo anterior, onde sessões paralelas competiam para fazer commit e misturavam regularmente ficheiros da zona de captura (notas diárias, MEMORY.md) com ficheiros de infra no mesmo commit. A árvore de trabalho é a superfície de coordenação — qualquer sessão pode ver o WIP de outra sessão imediatamente, sem sobrecarga de merge.
Quatro caminhos permitidos de mutação git estão explicitamente enumerados e aplicados por uma verificação com grep:
vault-sync.sh— commit autónomo noturno/commit— invocado apenas pelo utilizador, raramente (antes de operações destrutivas ou sincronização entre máquinas)audit-infra/checkpoint.sh— push e tag, sem commit/infra-pr— ramo, commit no ramo, MR no GitLab, para alterações de infra que precisam de revisão antes de chegar ao main
Qualquer skill, agente ou script que chame git commit|add|push|stash fora destes quatro caminhos é uma violação da doutrina.
Agendamento
Dois caminhos de agendamento complementares servem necessidades diferentes:
/at (local, piggyback no heartbeat): ações locais pontuais ou recorrentes — prompts Claude, comandos de shell, ou mensagens Telegram. As tarefas vivem em .cortex/data/at/tasks.json, que o dispatcher de heartbeat avalia a cada tick. Suporta datetimes ISO pontuais e um subconjunto de cron de 5 campos. Exemplo: “amanhã às 07:15, ler a nota diária de hoje e reportar pelo Telegram.” Este é o caminho certo para tudo o que precise da árvore de trabalho local, do bot Telegram, ou de CLIs locais.
/schedule (remoto alojado na Anthropic): tarefas de forma cloud que não precisam da árvore de trabalho local — abrir um PR, chamar uma API externa, publicar num serviço remoto. O agente remoto não consegue ler as edições de hoje no vault (que só chegam ao git às 02:00) e não consegue acionar o bot Telegram local.
A separação é importante: praticamente todos os pedidos do tipo “lembra-me amanhã de verificar X” ou “todas as segundas faz Y localmente” são /at, não /schedule.
O Gateway Pessoal
O vault não existe isoladamente. O gateway pessoal é uma CLI que normaliza o acesso a todas as ferramentas externas que o vault toca: tarefas, email, calendário e contactos, em qualquer conta específica em que vivam.
O gateway existe por uma razão: o OpenClaw tinha dificuldade com o encaminhamento multi-conta. O OpenClaw trata cada serviço externo, e cada conta dentro desse serviço, como uma integração própria, com a sua própria forma de comando, o seu próprio fluxo de autenticação e o seu próprio formato de resposta. Perguntar “o que está hoje no meu calendário?” quando “o meu calendário” é, na verdade, uma conta pessoal Google, uma conta de trabalho M365, um calendário familiar iCloud e três feeds ICS, transformava-se numa explosão de comandos por conta e parsing frágil de strings. O modelo passava mais tempo a desambiguar contas do que a responder à pergunta.
O gateway achata isso. Cada domínio tem um verbo, o verbo encaminha para todas as contas, e a resposta é uma forma JSON uniforme com a conta de origem identificada dentro de cada item:
# Tarefas (Todoist + Jira)
gateway tasks filter "today | overdue"
gateway tasks completed --since 2026-03-04 --by completion
# Calendário (Google + M365 + iCloud + feeds ICS arbitrários)
gateway calendar list --from 2026-04-30T00:00 --to 2026-05-01T00:00
# Email (Gmail + M365)
gateway email summary
# Contactos + CRM (Google + M365 + iCloud + Dex)
gateway contacts search "João"
Nove contas estão ligadas hoje. Acrescentar uma décima é uma entrada de configuração e uma volta de OAuth, sem alterações em skills. Remover uma é o inverso. Mudar do Todoist para outro gestor de tarefas significaria editar o adaptador tasks do gateway, não reescrever cada skill que mencione tarefas. As skills só conhecem domínios (tarefas, calendário, email, contactos) e intenções (list, search, add, update). O gateway é onde vive a realidade confusa dos OAuth scopes, refresh de tokens, rate limits, parsing de ICS, das idiossincrasias entre M365, Graph e Outlook, e das particularidades do Dex CRM.
Por baixo, há uma camada de segredos. Os tokens vivem num único secrets.json com uma cadeia de fallback em três níveis (variável de ambiente → ficheiro local → keychain do OS), escrita atómica sob flock para que refreshes OAuth concorrentes não corrompam o ficheiro (um incidente real em finais de abril de 2026), e snapshots rotativos de meia em meia hora para recuperação. Nada disto é visível para as skills; chamam gateway tasks list e confiam no resultado.
Para além do gateway, o vault integra alguns CLIs nativos cujas APIs não cabem na mesma forma:
- Withings — composição corporal, tendência de peso, dados de atividade
- Strava — atividades via CLI nativo (OAuth com refresh automático, output JSON)
- Granola — importação de notas de reuniões (cada reunião torna-se uma nota no vault com frontmatter
granola_id, deduplicada em reexecuções) - Book RAG — pesquisa semântica sobre uma biblioteca pessoal EPUB/PDF (Qdrant + TEI num NAS no homelab)
A separação é deliberada: o gateway cobre os quatro domínios onde a multiplexagem de contas é o problema real; o Strava e o Withings têm cada um uma única conta e uma única API, e envolvê-los na forma do gateway seria cerimónia, não valor.
Um Dia na Vida
Cinco interações ilustrativas para dar textura à arquitetura. Os nomes, projetos e labels de Quest abaixo são fictícios; as superfícies, caminhos de comandos e lógica de encaminhamento são exatamente os que correm no sistema real.
Marcação de evento em forma livre (Telegram, resposta em voz)
Acabei de marcar um 1:1 com o Alex para terça às 10:30 para discutir a proposta da API. Coloca no calendário.
O Cortex responde (voz via ElevenLabs TTS, transcrita):
“Feito. 1:1 com o Alex acrescentado ao calendário do trabalho para terça às 10:30, 30 minutos. A conta pessoal tinha uma consulta às 11:00, por isso mantive o slot apertado do lado profissional. Lembrete a dez minutos.”
Por baixo: o bot Telegram recebe a mensagem → o classificador automático identifica-a como ação de calendário → gateway calendar list inspeciona os slots livres nas quatro contas de calendário → gateway calendar add --account m365-work insere o evento → o ElevenLabs TTS rende a resposta, devolvida como mensagem de áudio.
Verificação de consistência do plano semanal (Telegram)
No plano desta semana, [[api-redesign-proposal]] continua marcado como em curso, mas mandei para revisão na segunda-feira. Porquê?
O Cortex:
“Encontrei a inconsistência. A nota do projeto tem
status: review-pendingdesde segunda de manhã, mas a linha de resultado na nota desta semana nunca foi actualizada. A fechar agora: resultado marcado como ’enviado para revisão’, o follow-up dependente (triagem do feedback de revisão) movido para a fila da próxima semana. O /closeweek apanhava-a no domingo; surge aqui antes.”
Por baixo: query ao índice do vault contra o frontmatter da nota do projeto, cruzamento com o estado open/closed da linha de resultado na nota desta semana, reescrita do ficheiro semanal, propagação para o Todoist via gateway tasks update.
Sugestão para o bloco de foco com base no calendário (Telegram)
O que devo fazer no bloco de foco das 09:00–12:00 hoje?
O Cortex:
“Três candidatos, ordenados por suporte de Quest e risco:
- [[vendor-evaluation-report]] — entrega na sexta, q-platform, ★ (sem segunda janela após esta manhã).
- [[onboarding-doc-rewrite]] — q-team, entrega na próxima semana, divisível por blocos.
- Duas notas seed marcadas para destilação — q-research, menor stakes.
Sugestão: #1 neste bloco com um stretch para #2 se sobrar tempo; #3 fica para uma leitura à noite. O resumo matinal de hoje já enquadrou da mesma forma.”
Por baixo: gateway calendar list --today confirma que o bloco de foco está mesmo no calendário, o índice do vault devolve as notas de projetos activos ordenadas pelo peso da Quest trimestral, cruza com as outcomes desta semana em Weekly/<semana-actual>.md, devolve a lista ordenada.
Correcção retroactiva do vault a partir de uma fonte externa (Telegram)
Esqueci-me de exportar a corrida para o Strava ontem. Puxa-a agora e corrige a nota de ontem.
O Cortex:
“Feito. O Strava agora mostra a corrida de manhã de ontem. Nota diária corrigida: a secção Health > Movement passa a reflectir a actividade, a cadência rolante de 7 dias está actualizada, o gatilho
training_gapdeixa de estar activo. O resumo matinal que já saiu não é re-editado; o gap aparece no /closeweek.”
Por baixo: strava activities list --after <ontem> devolve a actividade recém-sincronizada, edição na secção Health da nota diária de ontem, o scorecard recalcula a cadência rolante, o ficheiro de estado do health-agent é actualizado para impedir que o gatilho training_gap dispare no próximo tick.
Aviso autónomo de deriva (Telegram, sem input humano)
[11:30, sem aviso]
Atenção: o q-platform não anda há três dias. A vendor evaluation é entregue na sexta e segunda-quarta está totalmente ocupado com reuniões, o que deixa quinta de manhã como única janela. Vale a pena cortar 30 minutos do âmbito agora, ou empurrar o prazo?
Por baixo: a cada quatro ticks, o heartbeat lança a sessão Claude /heartbeat-agent → lê o Live Log recente, as outcomes desta semana e a densidade do calendário para os próximos quatro dias → deteta a paragem do q-platform contra um prazo a aproximar-se → compõe o aviso, encaminha por proactivity_governance (orçamento de um push por dia, gate de “deferir após o utilizador”) e pelo outbox (dedup por hash do corpo) antes de chegar ao Telegram.
Os primeiros quatro exemplos são iniciados pelo utilizador. O quinto é autónomo e só dispara quando o raciocínio do heartbeat-agent revela uma mudança real, nunca a cada tick. A arquitetura das secções anteriores explica como cada um corre; isto é o que parecem na prática.
O Sistema de Memória
As sessões Claude Code são sem estado por defeito. O Cortex contorna isto com um sistema de memória em camadas:
CLAUDE.md(~100 linhas, sempre carregado) — Governação, convenções de plataforma, regras chave.claude/rules/(carregado por padrão de ficheiro ou sempre) — Convenções de domínio específico (tarefas do gateway, língua, fluxos HITL, priorização)SKILL.md(carregado por invocação) — Fluxo de trabalho com múltiplas fases para essa skillMEMORY.md(sempre carregado) — Aprendizagens duradouras: padrões estáveis, insights de depuração, histórico de sessões
O MEMORY.md tem agora cerca de 50 entradas de tópicos, cada uma apontando para um ficheiro separado. O efeito cumulativo é real: insights de depuração de abril evitam repetir os mesmos erros em outubro. Observações comportamentais (os blocos de foco da manhã sustentam-se mais tempo do que os da tarde, a ordem dos commits importa em sessões paralelas) melhoram as decisões futuras.
Índice SQLite do Vault
A pesquisa do Obsidian é boa para conteúdo, mas fraca para consultas estruturais como “quais notas não têm backlinks?” ou “mostrar-me todas as notas seed com mais de 30 dias.” O Cortex mantém um índice SQLite com:
- Metadados de notas: tipo, estado, pasta, tags, contagem de palavras, datas
- Grafo de ligações: ligações diretas, backlinks, ligações quebradas
- Índice de entidades: pessoas e empresas por nome de ficheiro e título, para pesquisa em menos de um segundo antes de perguntar “quem é X?”
- Embeddings: vetores de 384 dimensões de
all-MiniLM-L6-v2para pesquisa semântica
As consultas relacionais (órfãos, ligações quebradas, pesquisa de entidades) correm 14x mais rápido do que o pipeline grep equivalente, com maior precisão. As pesquisas de texto simples ainda favorecem o grep por 3 a 10x devido à sobrecarga de arranque do Python. O índice reconstrói-se todas as noites via cortex-reindex.timer.
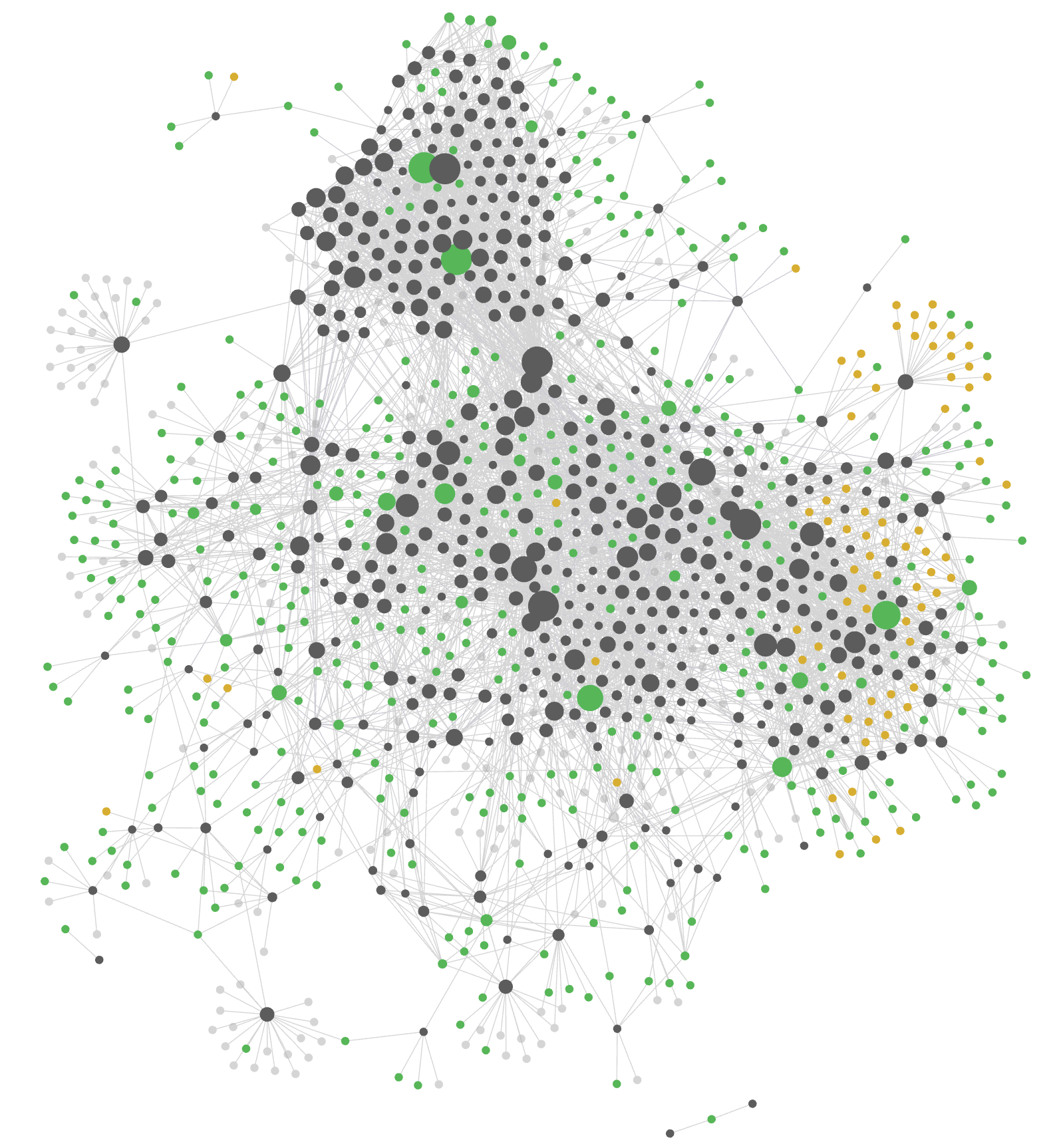
O vault do Cortex como grafo dirigido por forças após um ano de captura e ligação. Cada nó é uma nota; cada aresta é um wikilink entre notas. O tamanho do nó escala com o número de backlinks. A silhueta em forma de cérebro emerge apenas da estrutura de ligações, sem layout manual.
O Que Aprendi
A governação supera a flexibilidade. A regra da Inbox-first pareceu restritiva no início, mas é o padrão mais importante. Sem ela, as notas proliferam em localizações aleatórias e a estrutura do vault degrada-se em semanas.
O modelo de commits importa mais do que se espera. Três meses de dor com sessões paralelas — commits de proveniência mista, corridas entre sessões, MEMORY.md editado por cinco sessões no mesmo dia — dissolveram-se com uma decisão: sem commits durante o dia. Todas as edições vivem na árvore de trabalho; uma tarefa agendada é a única dona dos commits.
A fricção na captura é o inimigo. O classificador de captura automática pelo Telegram foi a adição com maior ROI nos últimos dois meses. A barreira para “enviar uma nota de voz” é muito mais baixa do que “abrir o Obsidian e criar uma nota.” O classificador trata do encaminhamento; o utilizador fornece o sinal em bruto.
Os agentes autónomos precisam de deduplicação por design. O heartbeat e o agente de saúde disparam alertas apenas quando os estados dos gatilhos mudam, não a cada tick. Sem isso, uma condição weight_above_goal geraria um alerta a cada hora. Dedup-por-data é o padrão mínimo viável para qualquer sinal autónomo.
As skills devem ser fases, não monolitos. Dividir os fluxos de trabalho em fases numeradas com chamadas de ferramentas paralelas explícitas torna-os mais rápidos e mais fáceis de depurar. O /closeday tem 11 fases; cada uma pode ser analisada de forma independente. Uma fase com erro falha de forma ruidosa em vez de corromper silenciosamente toda a síntese.
O meta-trabalho expande-se para preencher o tempo disponível. Construir o sistema é satisfatório. Usá-lo para fazer trabalho real é o objetivo. O sistema agora sinaliza isto por si próprio, com avisos de outcomes parados a chegar ao resumo matinal sempre que uma Quest fica em silêncio durante vários dias.
O melhor sistema é o que cresceu consigo próprio. O maior erro seria copiar o Cortex, ou qualquer outro projeto, e esperar que funcionasse. O valor acumula-se precisamente porque cada skill, cada regra, cada integração foi adicionada em resposta a um ponto de fricção real numa semana real. Mais ninguém tem o seu calendário, a sua estrutura no Todoist, a sua lista de leitura, os seus ritmos de planeamento de sprint. Um segundo cérebro construído para encaixar na vida de outra pessoa é um segundo cérebro que vai deixar de usar. Comece pequeno, sinta a fricção, acrescente a camada que a resolve.
Quando Não Construir Isto
A crítica escreve-se sozinha, e vale a pena dizê-la com honestidade.
Isto não é uma ferramenta amigável para o consumidor final. O Cortex são cerca de 56 skills, dezenas de pontos de entrada em Python, seis timers do systemd, um índice SQLite, um broker NATS JetStream, dois bots de longa duração e uma árvore de trabalho partilhada por cinco sessões Claude Code em simultâneo. Implementá-lo exige à vontade com unidades de utilizador no Linux, fluxos OAuth para meia dúzia de serviços, empacotamento Python via uv, e leitura suficiente da documentação do Claude Code para distinguir entre uma skill, um agente e um hook. Se depurar ficheiros de unidade do systemd ainda não faz parte da sua semana, este não é o sistema que vai querer manter.
Troca-se manutenção de notas por manutenção de software. O Cortex retira o peso de arquivar notas manualmente, podar seeds e escrever a síntese semanal. Não retira o peso de manter o sistema a correr. Em finais de abril, a infraestrutura interna acumulava cinco parsers de YAML, treze clientes HTTP ad-hoc, dez padrões de carregamento de variáveis de ambiente e doze wrappers de shell, todos a precisar de deduplicação. O refactor Cortex 2.0 não foi opcional, e um sistema desta dimensão exige refactor periódico tal como código de produção.
Não vai portar-se para a sua vida. As skills estão amarradas aos meus IDs de projeto no Todoist, aos meus objetivos Withings, à minha cadência Strava, às minhas contas de calendário, às minhas Quarterly Quest labels, e ao meu ritmo diário. Levar o harness para uma vida diferente não é um copy-paste; é uma reescrita de cada skill que toca em estado externo. A forma publicável do harness existe (o Cortex 2.0 separou o vault da infraestrutura precisamente para que a infraestrutura pudesse ser open-source), mas o valor vive no fio que liga as peças, e esse fio tem de ser seu.
Vai parecer rígido se trabalhar de forma fluida. A regra Inbox-first é inegociável. Os fechos diário, semanal e trimestral correm em horário fixo. Cada nota carrega frontmatter obrigatório; cada integração externa passa por um gateway. Se o seu trabalho é improvisado, exploratório ou visual-first, esta disciplina vai parecer overhead. A governação compra consistência ao preço de fricção, e essa fricção é sempre paga pelo humano no momento da captura.
No que o Cortex é bom: tornar legível à máquina uma vida que já é estruturada, fazer emergir padrões em escalas longas de tempo, e transformar o trabalho aborrecido da revisão semanal em algo que decorre enquanto se dorme. No que não é: um truque de produtividade que se adopta num fim-de-semana.
Diagrama de Arquitetura
Quatro colunas, da esquerda para a direita: como as mensagens entram (CLI, Telegram, email), o que raciocina sobre elas (Claude Code com skills, agentes, memória), o que é lido e escrito (o vault Obsidian e o seu índice), e as integrações e automações que mantêm o resto do mundo ligado. As setas mostram o caminho em tempo de execução de uma única interação: uma mensagem chega a uma interface, o Claude Code seleciona a skill relevante, o vault é lido ou atualizado, e as integrações ramificam-se para o Todoist, Gmail, Strava, ou o que a skill precisar. Tudo na coluna Automation à direita corre com o seu próprio timer systemd, sem intervenção humana.

Código-fonte
O Cortex é um repositório privado (contém dados reais da minha vida), mas os padrões são transferíveis. Os ingredientes chave são:
- Um vault Obsidian com estrutura consistente (PARA ou similar)
- Claude Code com configuração
.claude/(skills, agentes, regras, memória) - Uma CLI gateway que envolva as suas ferramentas de produtividade
- Um índice SQLite para consultas estruturais
- Git para versionamento, com um modelo de sincronização noturna se correr sessões paralelas
- Um message bus leve (NATS ou equivalente) se quiser agentes de domínio autónomos a comunicar
A infraestrutura tem aproximadamente 4.000 linhas de definições de skills, 2.000 linhas de Python e 500 linhas de shell. O vault tem mais de 350 notas em todas as categorias.
O bot Telegram baseia-se no claude-code-telegram de Richard Tackett, com contribuições de volta ao upstream (melhorias na transcrição de voz, PR pendente). A CLI do gateway pessoal, que trata o Todoist, Gmail, M365, Google Calendar, iCloud e Dex CRM numa interface unificada, será publicada como open-source numa fase posterior. Dependendo da utilidade que o sistema completo provar ter para outros, a camada de skills e agentes do Cortex poderá seguir.
Se estiver interessado em construir algo semelhante, a documentação do Claude Code cobre skills, agentes e o sistema de memória. O trabalho real não está no código — está em definir as regras de governação e os fluxos de trabalho que correspondem à forma como efetivamente pensa.