Processamento de Áudio com Python
Processamento de ficheiros wave e implementação de filtros FIR

Processamento de áudio com Python
Introdução
O tempo estava mau hoje. Por isso fiquei em casa e decidi aprender algo novo. Lembro-me de estudar filtros digitais na faculdade e era de alguma forma aborrecido. Na altura não era tão fácil criar exemplos úteis e práticos.
Felizmente hoje em dia existe Python e é realmente fácil brincar com processamento de som como pode ser visto nesta página.
A maior parte do código encontrado nesta página foi criado usando fragmentos encontrados na internet.
Processamento de ficheiros wave e criação de espectrogramas
import numpy as np
import matplotlib.pyplot as plt
import wave
from scipy.io import wavfile
import contextlib
# from http://stackoverflow.com/questions/2226853/interpreting-wav-data/2227174#2227174
def interpret_wav(raw_bytes, n_frames, n_channels, sample_width, interleaved = True):
if sample_width == 1:
dtype = np.uint8 # unsigned char
elif sample_width == 2:
dtype = np.int16 # signed 2-byte short
else:
raise ValueError("Only supports 8 and 16 bit audio formats.")
channels = np.frombuffer(raw_bytes, dtype=dtype)
if interleaved:
# channels are interleaved, i.e. sample N of channel M follows sample N of channel M-1 in raw data
channels.shape = (n_frames, n_channels)
channels = channels.T
else:
# channels are not interleaved. All samples from channel M occur before all samples from channel M-1
channels.shape = (n_channels, n_frames)
return channels
def get_start_end_frames(nFrames, sampleRate, tStart=None, tEnd=None):
if tStart and tStart*sampleRate<nFrames:
start = tStart*sampleRate
else:
start = 0
if tEnd and tEnd*sampleRate<nFrames and tEnd*sampleRate>start:
end = tEnd*sampleRate
else:
end = nFrames
return (start,end,end-start)
def extract_audio(fname, tStart=None, tEnd=None):
with contextlib.closing(wave.open(fname,'rb')) as spf:
sampleRate = spf.getframerate()
ampWidth = spf.getsampwidth()
nChannels = spf.getnchannels()
nFrames = spf.getnframes()
startFrame, endFrame, segFrames = get_start_end_frames(nFrames, sampleRate, tStart, tEnd)
# Extract Raw Audio from multi-channel Wav File
spf.setpos(startFrame)
sig = spf.readframes(segFrames)
spf.close()
channels = interpret_wav(sig, segFrames, nChannels, ampWidth, True)
return (channels, nChannels, sampleRate, ampWidth, nFrames)
def convert_to_mono(channels, nChannels, outputType):
if nChannels == 2:
samples = np.mean(np.array([channels[0], channels[1]]), axis=0) # Convert to mono
else:
samples = channels[0]
return samples.astype(outputType)
def plot_specgram(samples, sampleRate, tStart=None, tEnd=None):
plt.figure(figsize=(20,10))
plt.specgram(samples, Fs=sampleRate, NFFT=1024, noverlap=192, cmap='nipy_spectral', xextent=(tStart,tEnd))
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.show()
def plot_audio_samples(title, samples, sampleRate, tStart=None, tEnd=None):
if not tStart:
tStart = 0
if not tEnd or tStart>tEnd:
tEnd = len(samples)/sampleRate
f, axarr = plt.subplots(2, sharex=True, figsize=(20,10))
axarr[0].set_title(title)
axarr[0].plot(np.linspace(tStart, tEnd, len(samples)), samples)
axarr[1].specgram(samples, Fs=sampleRate, NFFT=1024, noverlap=192, cmap='nipy_spectral', xextent=(tStart,tEnd))
#get_specgram(axarr[1], samples, sampleRate, tStart, tEnd)
axarr[0].set_ylabel('Amplitude')
axarr[1].set_ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.show()
tStart=0
tEnd=20
channels, nChannels, sampleRate, ampWidth, nFrames = extract_audio('sultans.wav', tStart, tEnd)
samples = convert_to_mono(channels, nChannels, np.int16)
plot_audio_samples("Sultans of Swing - First 20s", samples, sampleRate, tStart, tEnd)
wavfile.write('sultans_20s.wav', sampleRate, samples)
!ffmpeg -y -loglevel panic -i sultans_20s.wav sultans_20s.mp3
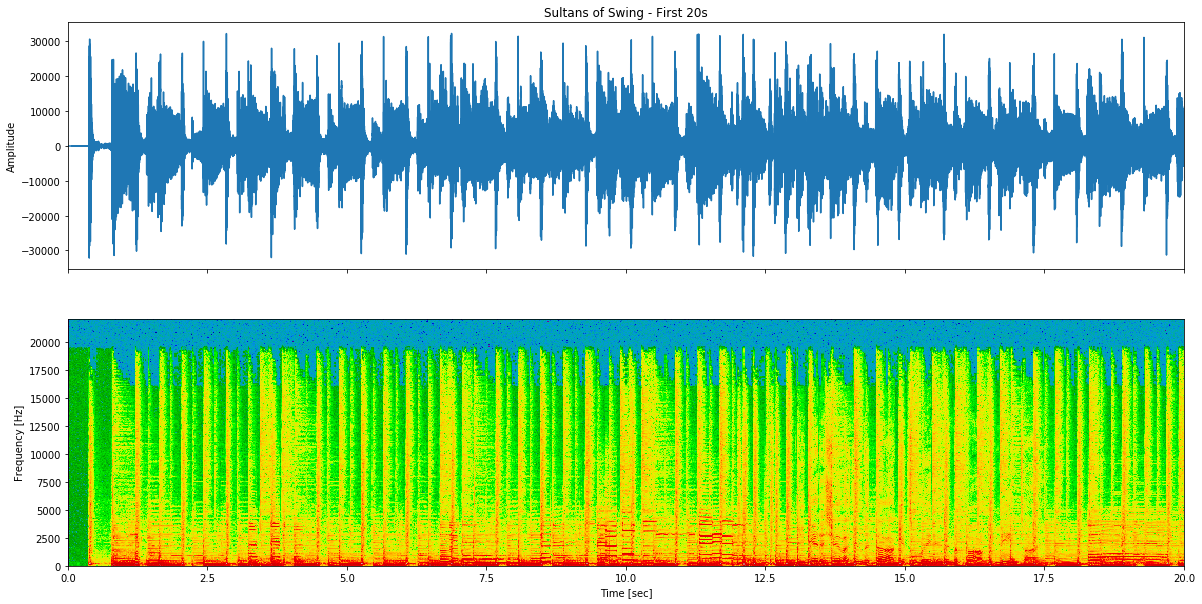
Figura 1: Análise de forma de onda e espectrograma de Sultans of Swing - primeiros 20 segundos mostrando a amplitude ao longo do tempo e distribuição de frequências.
Áudio processado:
Espectrogramas: Exemplo 2
tStart=0
tEnd=20
channels, nChannels, sampleRate, ampWidth, nFrames = extract_audio('about.wav', tStart, tEnd)
samples = convert_to_mono(channels, nChannels, np.int16)
plot_audio_samples("About a Girl - First 20s", samples, sampleRate, tStart, tEnd)
wavfile.write('about_20s.wav', sampleRate, samples)
!ffmpeg -y -loglevel panic -i about_20s.wav about_20s.mp3
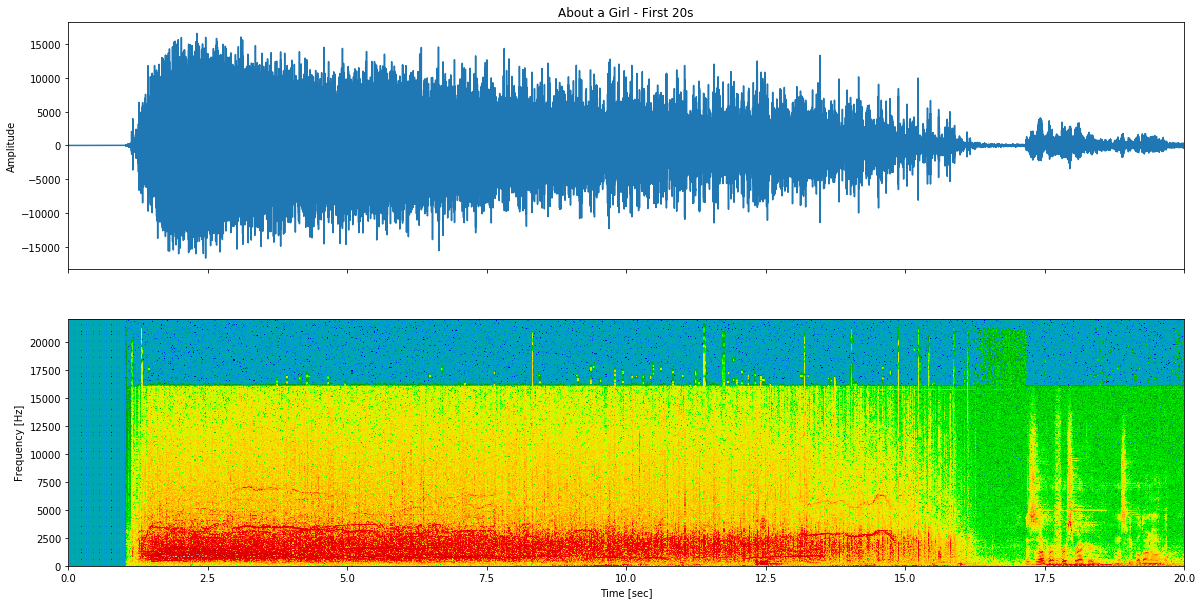
Figura 2: Análise de forma de onda e espectrograma de About a Girl - primeiros 20 segundos mostrando os componentes característicos do assobio no domínio da frequência.
Áudio processado:
Filtragem do assobio na intro de “About a Girl”
Agora vamos usar um filtro digital para extrair o assobio entre os 13 e 15s na intro de “About a Girl”. Neste caso é usado um FIR passa-banda. O passa-baixo, passa-alto e rejeita-banda também são implementados pois serão usados mais tarde.
def fir_high_pass(samples, fs, fH, N, outputType):
# Referece: https://fiiir.com
fH = fH / fs
# Compute sinc filter.
h = np.sinc(2 * fH * (np.arange(N) - (N - 1) / 2.))
# Apply window.
h *= np.hamming(N)
# Normalize to get unity gain.
h /= np.sum(h)
# Create a high-pass filter from the low-pass filter through spectral inversion.
h = -h
h[int((N - 1) / 2)] += 1
# Applying the filter to a signal s can be as simple as writing
s = np.convolve(samples, h).astype(outputType)
return s
def fir_low_pass(samples, fs, fL, N, outputType):
# Referece: https://fiiir.com
fL = fL / fs
# Compute sinc filter.
h = np.sinc(2 * fL * (np.arange(N) - (N - 1) / 2.))
# Apply window.
h *= np.hamming(N)
# Normalize to get unity gain.
h /= np.sum(h)
# Applying the filter to a signal s can be as simple as writing
s = np.convolve(samples, h).astype(outputType)
return s
def fir_band_reject(samples, fs, fL, fH, NL, NH, outputType):
# Referece: https://fiiir.com
fH = fH / fs
fL = fL / fs
# Compute a low-pass filter with cutoff frequency fL.
hlpf = np.sinc(2 * fL * (np.arange(NL) - (NL - 1) / 2.))
hlpf *= np.blackman(NL)
hlpf /= np.sum(hlpf)
# Compute a high-pass filter with cutoff frequency fH.
hhpf = np.sinc(2 * fH * (np.arange(NH) - (NH - 1) / 2.))
hhpf *= np.blackman(NH)
hhpf /= np.sum(hhpf)
hhpf = -hhpf
hhpf[int((NH - 1) / 2)] += 1
# Add both filters.
if NH >= NL:
h = hhpf
h[int((NH - NL) / 2) : int((NH - NL) / 2 + NL)] += hlpf
else:
h = hlpf
h[int((NL - NH) / 2) : int((NL - NH) / 2 + NH)] += hhpf
# Applying the filter to a signal s can be as simple as writing
s = np.convolve(samples, h).astype(outputType)
return s
def fir_band_pass(samples, fs, fL, fH, NL, NH, outputType):
# Referece: https://fiiir.com
fH = fH / fs
fL = fL / fs
# Compute a low-pass filter with cutoff frequency fH.
hlpf = np.sinc(2 * fH * (np.arange(NH) - (NH - 1) / 2.))
hlpf *= np.blackman(NH)
hlpf /= np.sum(hlpf)
# Compute a high-pass filter with cutoff frequency fL.
hhpf = np.sinc(2 * fL * (np.arange(NL) - (NL - 1) / 2.))
hhpf *= np.blackman(NL)
hhpf /= np.sum(hhpf)
hhpf = -hhpf
hhpf[int((NL - 1) / 2)] += 1
# Convolve both filters.
h = np.convolve(hlpf, hhpf)
# Applying the filter to a signal s can be as simple as writing
s = np.convolve(samples, h).astype(outputType)
return s
tStart = 12
tEnd = 15
channels, nChannels, sampleRate, ampWidth, nFrames = extract_audio('about.wav', tStart, tEnd)
samples = convert_to_mono(channels, nChannels, np.int16)
plot_audio_samples("About a Girl section - Before Filtering", samples, sampleRate, tStart, tEnd)
wavfile.write('about_original.wav', sampleRate, samples)
!ffmpeg -y -loglevel panic -i about_original.wav about_original.mp3
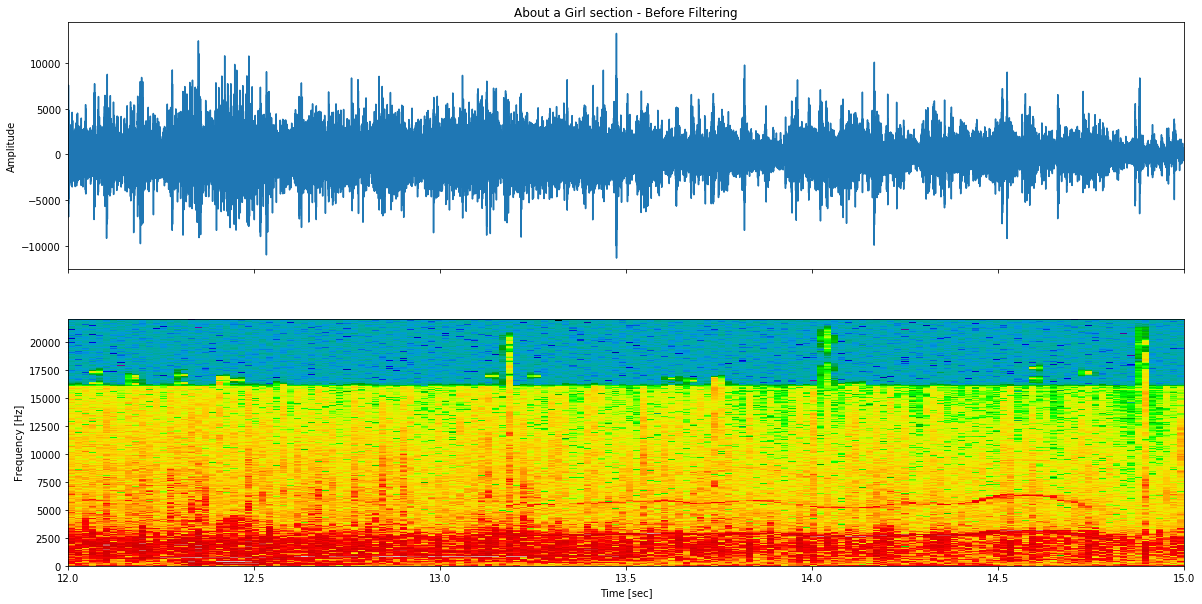
Figura 3: Segmento de áudio de About a Girl antes da filtragem - componentes de assobio visíveis a 2400-2900Hz, 5000Hz e 7500Hz no espectrograma.
Antes da filtragem:
É possível ver o assobio no espectrograma. Existem três componentes nas seguintes bandas:
- 2400 a 2900Hz
- À volta dos 5000Hz
- À volta dos 7500Hz
O som predominante encontra-se na primeira banda, e é essa que vamos tentar filtrar.
samples_filtered = fir_band_pass(samples, sampleRate, 2400, 2900, 461, 461, np.int16)
samples_filtered = samples_filtered * 2 # Sound amplification
plot_audio_samples("About a Girl section - After Filtering", samples_filtered, sampleRate, tStart, tEnd)
wavfile.write('about_whistle.wav', sampleRate, samples_filtered)
!ffmpeg -y -loglevel panic -i about_whistle.wav about_whistle.mp3
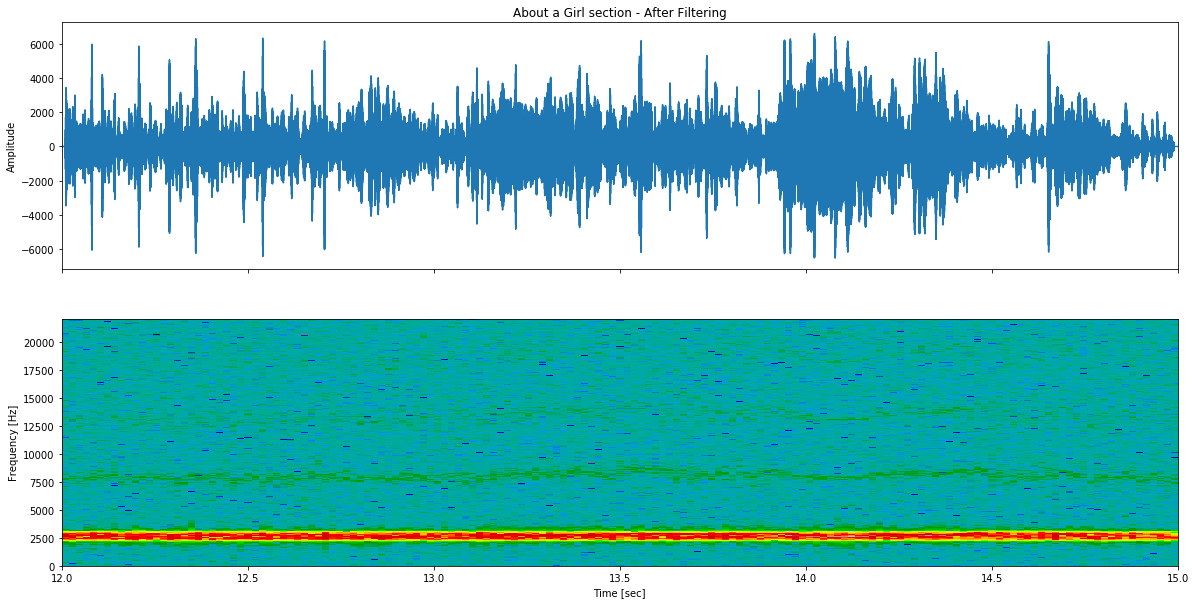
Figura 4: Segmento de áudio de About a Girl após filtragem FIR passa-banda (2400-2900Hz) - componente de assobio isolado com sinal amplificado.
Após filtragem:
O resultado não é perfeito. Mas é possível perceber a ideia.
Remoção de voz da música: tentativa 1
tStart = 0
tEnd = 20
channels, nChannels, sampleRate, ampWidth, nFrames = extract_audio('sultans.wav', tStart, tEnd)
samples = convert_to_mono(channels, nChannels, np.int16)
plot_audio_samples("Sultans of Swing - Before Filtering", samples, sampleRate, tStart, tEnd)
wavfile.write('sultans_original.wav', sampleRate, samples)
!ffmpeg -y -loglevel panic -i sultans_original.wav sultans_original.mp3
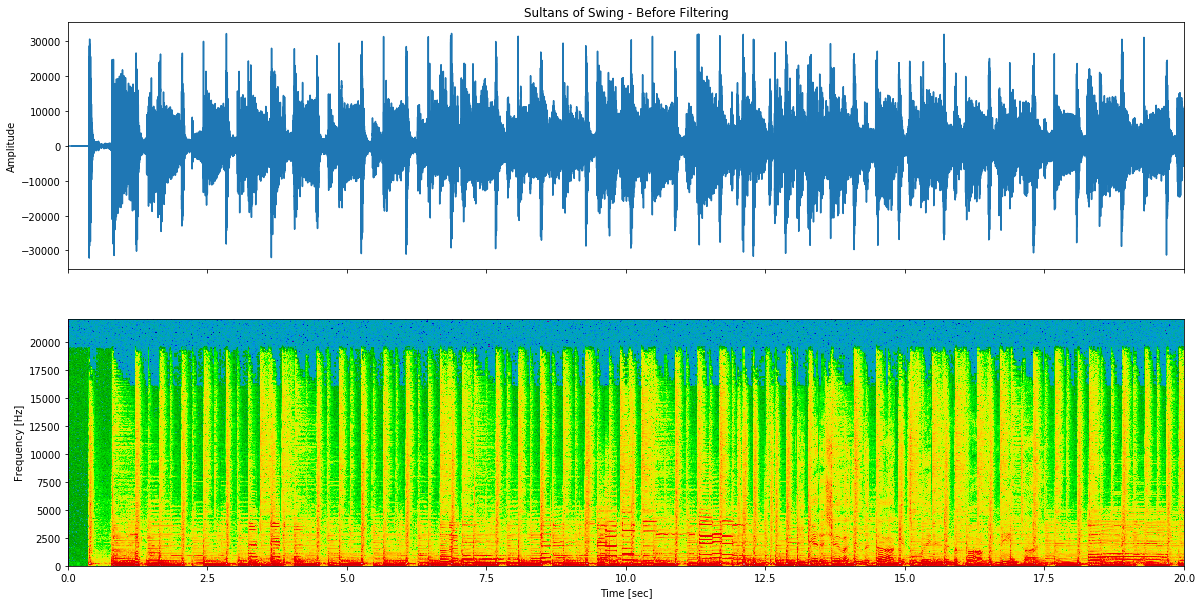
Figura 5: Áudio original de Sultans of Swing antes da remoção de voz - espectro de frequência completo incluindo gama vocal.
Antes da filtragem:
Nesta tentativa, é usado um filtro de banda passante muito acentuado para remover as frequências associadas à voz. Após alguns ajustes, as frequências de corte foram seleccionadas para cerca de 300Hz para o filtro passa-baixo e 6660Hz para o filtro passa-alto. Foram usadas duas passagens neste caso.
lp_samples_filtered = fir_low_pass(samples, sampleRate, 300, 461, np.int16) # First pass
lp_samples_filtered = fir_low_pass(lp_samples_filtered, sampleRate, 250, 461, np.int16) # Second pass
hp_samples_filtered = fir_high_pass(samples, sampleRate, 6600, 461, np.int16) # First pass
hp_samples_filtered = fir_high_pass(hp_samples_filtered, sampleRate, 6600, 461, np.int16) # Second pass
samples_filtered = np.mean(np.array([lp_samples_filtered, hp_samples_filtered]), axis=0).astype(np.int16)
plot_audio_samples("Sultans of Swing - After Filtering 1", samples_filtered, sampleRate, tStart, tEnd)
wavfile.write('sultans_novoice1.wav', sampleRate, samples_filtered)
!ffmpeg -y -loglevel panic -i sultans_novoice1.wav sultans_novoice1.mp3
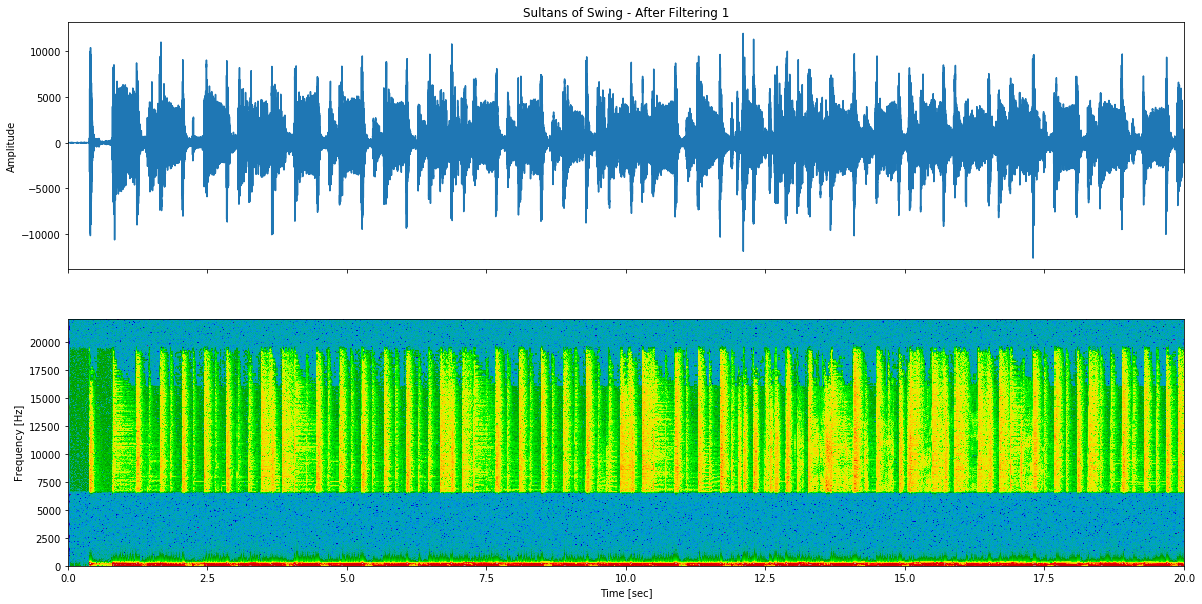
Figura 6: Sultans of Swing após tentativa de remoção de voz 1 - usando filtros FIR passa-baixo de dupla passagem (300Hz) e passa-alto (6600Hz) para eliminar frequências vocais.
Após filtragem:
O som resultante não soa muito natural. Mas a voz foi filtrada!
Remoção de voz da música: tentativa 2
Aparentemente, uma técnica amplamente usada para remover voz das músicas é misturar ambos os canais (esquerdo e direito) em conjunto. Como a voz é muito semelhante em ambos os canais, ao subtraí-los, a voz irá cancelar-se.
channels, nChannels, sampleRate, ampWidth, nFrames = extract_audio('sultans.wav', tStart, tEnd)
samples_no_voice = (channels[0]-channels[1]).astype(np.int16)
plot_audio_samples("Sultans of Swing - After Filtering 2", samples_no_voice, sampleRate, tStart, tEnd)
wavfile.write('sultans_novoice2.wav', sampleRate, samples_no_voice)
!ffmpeg -y -loglevel panic -i sultans_novoice2.wav sultans_novoice2.mp3
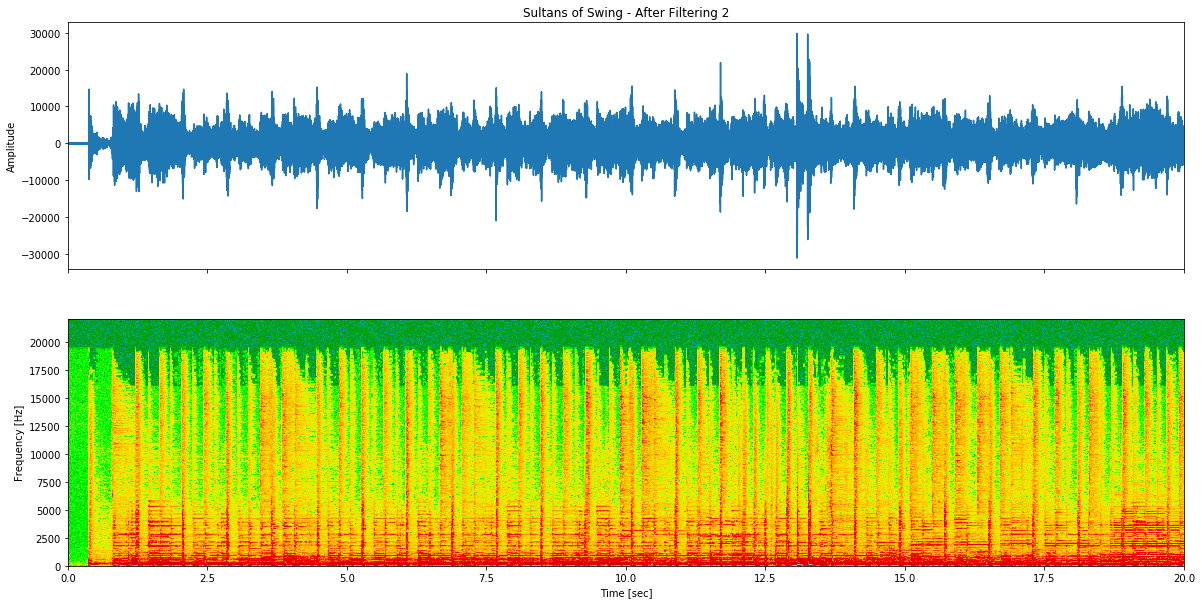
Figura 7: Sultans of Swing após tentativa de remoção de voz 2 - usando técnica de subtracção de canais estéreo onde canal esquerdo menos canal direito cancela vocais panoramizados ao centro.
Após filtragem:
Gosto muito do resultado porque há muito reverb e eco.
Remoção de voz da música: mistura de tentativas
Na terceira tentativa, ambas as tentativas #1 e #2 são misturadas em conjunto.
lp_samples_filtered.resize(samples_no_voice.shape)
hp_samples_filtered.resize(samples_no_voice.shape)
samples = ((samples_no_voice+lp_samples_filtered+hp_samples_filtered)/3).astype(np.int16)
plot_audio_samples("Sultans of Swing - After Filtering 1+2", samples_no_voice, sampleRate, tStart, tEnd)
wavfile.write('sultans_novoice3.wav', sampleRate, samples_no_voice)
!ffmpeg -y -loglevel panic -i sultans_novoice3.wav sultans_novoice3.mp3
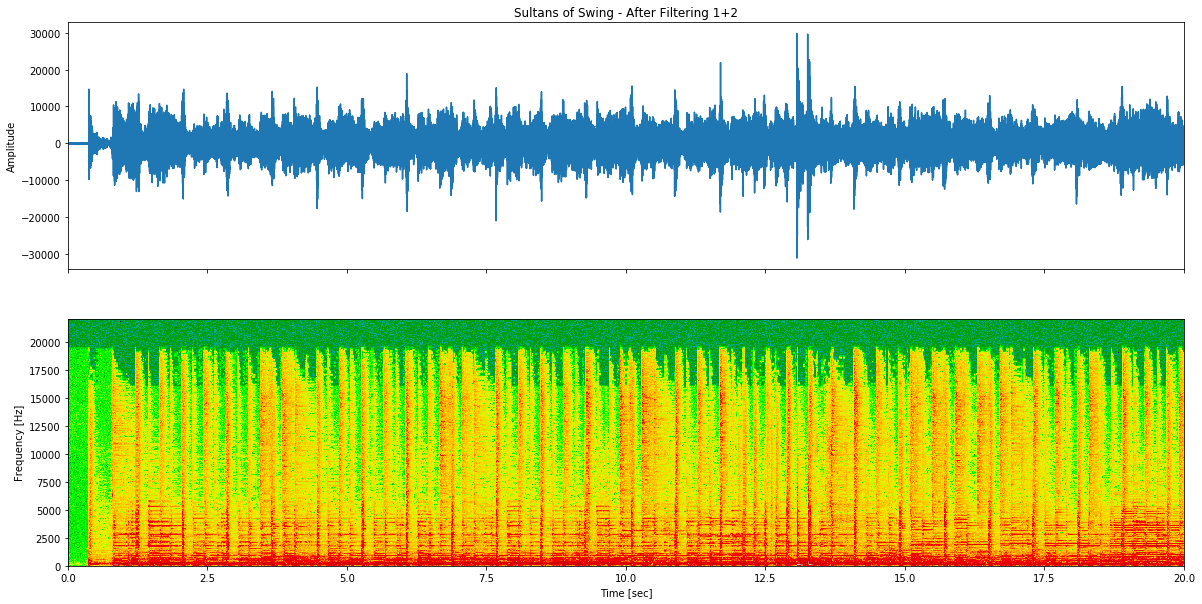
Figura 8: Sultans of Swing após combinar métodos de remoção de voz - misturando filtragem de frequência e técnicas de subtracção de canais estéreo para supressão vocal melhorada.
Após filtragem:
Parece quase o mesmo que a tentativa #2.
Feito com Jupyter Notebooks.
| Software | Versão |
|---|---|
| Python | 3.6.4 64bit [GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] |
| IPython | 6.2.1 |
| OS | Darwin 17.4.0 x86_64 i386 64bit |
| scipy | 1.0.0 |
| numpy | 1.14.0 |
| matplotlib | 2.1.2 |
| version_information | 1.0.3 |