Cortex: Building a Second Brain with Claude Code and Obsidian
An autonomous knowledge-management system built on skills, agents, and a heartbeat scheduler

What’s a Second Brain?
The term was popularized by Tiago Forte in Building a Second Brain: the idea is to offload the work of remembering, connecting, and retrieving information to an external system, so your biological brain can focus on thinking rather than storage.
In practice, this means keeping a structured, searchable collection of notes, meeting records, project plans, ideas, and references, all in one place and consistently organized. The most common framework is PARA: Projects (active, time-bound work), Areas (ongoing responsibilities), Resources (reference material), and Archives (completed or inactive items). Obsidian is one of the most popular tools for implementing it because it stores everything as plain markdown files that you fully own, links notes bidirectionally, and works offline.
The promise is compelling: decades of knowledge, instantly accessible, with connections surfacing across domains you forgot were related. The reality, for most people, is an inbox with 300 unsorted notes and a growing sense of guilt. The system does not maintain itself.
The Problem
I’ve been using Obsidian as a second brain for over a year. Like most knowledge workers, I started with good intentions: capture everything, link ideas, review regularly. The reality was different. Notes piled up in the inbox, daily reviews didn’t happen, and connections between ideas stayed invisible.
That year was also unusually crowded. By day I’m an analog IC designer; through 2024 and 2025 I was also working through a dual Executive MBA (Porto Business School plus Kozminski University, completed early 2026) on top of family life and a handful of side projects. Capture splintered across notes apps, voice memos, and three different task managers. Synthesis rarely happened at all. The second brain became one more thing to feed rather than the thing organizing everything else.
The friction wasn’t in the tool. It was in the maintenance. A second brain only works if you feed it, prune it, and traverse it regularly. That’s exactly the kind of repetitive, structured work that an AI agent can handle.
What Cortex Is
Cortex is my Obsidian vault, managed by Claude Code through a system of skills (repeatable workflows), agents (specialized reasoning), and integrations (calendar, tasks, email, fitness tracking). It runs from the terminal, from Telegram (with voice and TTS), from email, and autonomously on a schedule via Linux systemd user units.
The vault follows PARA as a base, adapted with an explicit time-review layer on top:
0-Inbox/ → Capture landing zone
1-Projects/ → Active, time-bound work
2-Areas/ → Ongoing responsibilities (health, family, career)
3-Resources/ → Reference material, topics of interest
4-Archives/ → Completed or inactive items
Daily/ → Daily notes (YYYY-MM-DD.md)
Weekly/ → Weekly notes (YYYY-WNN.md) — synthesized from dailies
Quarterly/ → Quarterly notes (YYYY-QN.md) — goals, quests, review
Yearly/ → Yearly notes (YYYY.md) — annual themes and retrospective
MOCs/ → Maps of Content for topic clusters
Templates/ → Note templates
The time-review layer is where the system earns its keep. Each tier is synthesized from the one below: /closeday writes the daily, /closeweek pulls from the week’s dailies, /closequarter from the weeks, and so on. No manual copy-paste; the cadence runs autonomously.
What makes it different from a standard Obsidian setup is the governance layer: Claude Code follows strict rules about where notes can be created, how they’re structured, and when they can be moved. New content always lands in the Inbox. Only the human decides where it belongs.
Prior Art: OpenClaw, NanoClaw, and the Cost Problem
Before building Cortex, I spent time with OpenClaw — the most popular self-hosted gateway for connecting chat apps to AI models. OpenClaw is impressive in scope: it connects WhatsApp, Telegram, Slack, iMessage, and a dozen other platforms to any LLM, and gives the model access to files, calendar, email, and browser.
In practice, I ran into three problems.
Transparency. OpenClaw orchestrates a lot behind the scenes. I couldn’t easily follow what the agent was doing at each step, which made debugging difficult and trust harder to build. When something didn’t work, the failure surface was large.
Model compatibility. The project claims support for any LLM, but in practice the results with non-Claude models were inconsistent for anything beyond simple queries. The more complex the workflow, the more it fell apart.
Cost. Running it with Claude at API rates is prohibitively expensive for the kind of daily-use pattern I needed: morning brief, live log capture throughout the day, meeting imports, evening synthesis. Each interaction billed per token adds up quickly at that frequency.
NanoClaw solved the cost problem directly. It runs on the Anthropic Claude Agent SDK, which means it works with a Claude Code subscription (Claude Max) rather than per-token API billing. That changes the economics entirely. At flat subscription cost, the per-interaction overhead disappears. NanoClaw is also significantly leaner than OpenClaw (around 500 lines of TypeScript), easier to understand, and built for container isolation.
Cortex took NanoClaw’s approach as its starting point and inverted the architecture. The deeper distinction is conceptual. OpenClaw and NanoClaw are infrastructure-first: a messaging gateway that connects chat channels to a model, with files, calendar, and email as features bolted onto the gateway. Cortex is information-first: an Obsidian vault is the base (the actual second brain), and everything else (Telegram bot, email bot, agents, schedulers, integrations) is infrastructure built around the vault. The vault is the center of gravity and Claude Code is the engine. The Telegram bot and email bot are capture channels that feed the vault, not the other way around. The Claude Code subscription makes the economics work at the usage level Cortex requires.
Two other projects are worth studying if you want to go further. claude-obsidian by Daniel Agrici takes a different angle: automatic knowledge organization based on Andrej Karpathy’s LLM Wiki pattern, zero manual filing, multi-model support. It is a good reference for the knowledge-graph and ingestion side of the problem. The MindStudio guide on building a second brain with Claude Code and Obsidian covers the fundamentals clearly, including CLAUDE.md structure and session continuity patterns. A solid starting point if you are coming to this fresh.
The more important point: none of these systems should be copied wholesale. The value of a second brain is that it reflects how you think, what you work on, and what you need to remember. OpenClaw, NanoClaw, claude-obsidian, and Cortex are all starting points. The system that works is the one that grew organically from your own frustrations, your own workflows, and your own sense of what is worth automating. Start with the smallest possible thing that helps you today. Add the next layer when you feel the friction.
The Skill System
Skills are the core of Cortex. Each skill is a markdown file (.claude/skills/<name>/SKILL.md) that defines a multi-phase workflow Claude Code executes when invoked with /<name>. They’re structured prompts with dynamic context injection.
Cortex currently has over 50 skills across several categories.
Daily Lifecycle
Three skills manage the daily rhythm:
/today — Morning brief: gather context in parallel (calendar across all accounts, Todoist tasks, Strava activities, vault changes), surface the day’s priorities and risks, write a daily note with a Closed List and a quote.
/closeday — End-of-day synthesis (11 phases): gather all data in parallel, merge calendar event notes into the Live Log, write a frozen Done snapshot from Todoist completions, compose the full synthesis (What moved, blocked, surprised; wins; meetings; rolling 7-day pattern), import Granola meeting notes, update health and principles sections, write tomorrow’s handoff, and polish the Live Log. Runs autonomously at 23:45 via the heartbeat scheduler.
/wrapup — Session memory: scans what changed, extracts durable patterns, appends a Live Log line. Does not touch git.
The daily note itself follows a nine-section spine: Journal, Executive Summary, Health, Principles, Daily Brief, End-of-Day Synthesis, Done, Tomorrow’s Handoff, Live Log. Each section is populated by a specific skill or user action; nothing stays blank by end of day.
/today at 05:00 and /closeday at 23:45; in between, humans and bots stream signals into the Live Log of the day’s vault note.Live Log & Auto-Capture
Throughout the day, signals flow into a ## 📡 Live Log section in the daily note. Four lightweight skills handle explicit capture:
/log <text>— general signal/focus <label>— mark the start of a deep-work session/block <text>— log an interruption or external constraint/energy <1-5>— quick energy check-in (writes to frontmatter)
The more interesting mechanism is automatic capture via Telegram. The bot runs a classifier on every free-form message:
- SKIP — short acks, task instructions, pure questions: do nothing, just reply
- LOG — a concrete fact (name, number, date, decision): append to the Live Log via
live-log.py - SEED-NOTE — substantial new content deserving its own note: create in
0-Inbox/
Voice messages are transcribed via Whisper, classified, and logged verbatim — preserving the user’s voice and language. The target is 2-5 Live Log entries per day; more than 10 signals narration creep.
HITL Workflows
Several skills are designed as interactive sessions where the human stays in the loop:
/sweep— Todoist Inbox triage: classifies each item into time-horizon projects, proposes a diff table, confirms before applying/week— Weekly planning: gathers context (Todoist, calendar, previous close note, active projects), asks structured questions, proposes Todoist mutations, confirms before writing. State persists in a JSON file so the conversation can span hours./quarter— Same contract at quarterly horizon/closeday— Also reads evening HITL input (energy, wins, brain_dump) from a JSON file the bot populates as messages arrive between 20:00 and 23:45
The HITL contract is clear: the conversation stays on the channel it started on. From Telegram, the interaction is Telegram. From CLI, it’s the terminal. Skills never hardcode a specific output channel.
Vault Maintenance
/vault-status— Instant diagnostic: orphan notes, broken links, stale seeds, oversized notes, inbox backlog/mature— Progressive summarization: selects 3-5 stale seed notes and guides layered review (bold key passages, highlight insights, write distilled summary, promote to evergreen)/reindex— Rebuilds a SQLite index of the vault for fast metadata queries/audit-knowledge— Semantic duplicates, un-MOC’d topic clusters, link decay/dream— Memory consolidation: reflective pass over recent activity to synthesize durable patterns
The Multi-Agent Architecture
Cortex is built on a three-phase multi-agent model, implemented as concentric loops running on different timescales.
Phase 1 — Drift signals (every 15 min): A heartbeat script evaluates three rule-based conditions — overdue tasks, email backlog, and silence — and pushes a Telegram alert only when the fired-signal set changes versus the last tick. No alert storm, no noise.
Phase 2 — Reasoning (every N ticks): The heartbeat spawns a /heartbeat-agent Claude session for drift reasoning beyond what rules can express. This is where “you haven’t touched q-platform in 3 days and the week is almost over” gets surfaced as a natural-language nudge.
Phase 3 — Domain agents: Specialized autonomous agents that run on their own schedule and communicate via a local NATS broker with JetStream. The first deployed agent is the Health Agent.
The Health Agent runs hourly, pulls Withings body-composition and Strava training data, publishes a snapshot to cortex.health.snapshot, and spawns a Claude session only when a trigger newly fires — weight_trending_up, training_gap, water_deficit, body fat drift. The Claude session receives the trigger payload via an environment variable and decides what to do with it. The evaluator is thin and deterministic; all reasoning lives in Claude.
All three phases run under a single cortex-heartbeat.timer (for Phase 1-2) and cortex-health-agent.timer (for Phase 3). The NATS broker enables future agents to subscribe to the health stream or publish their own, without re-implementing data pulls.
The diagram shows the principle that holds across all three phases: a thin deterministic evaluator decides whether reasoning is needed, and only then does a Claude session spawn. Phase 1 alerts only when the fired-signal set changes; Phase 2 reasons only every Nth tick; Phase 3 spawns only when a trigger newly crosses. Without this dedup-by-design, autonomous agents drown the user in repeat alerts within a day.
Nine specialized agents are available to skills:
| Agent | Purpose |
|---|---|
vault-explorer | Deep vault pattern scanning, connection tracing |
vault-organizer | Note creation, inbox organization, applying templates |
book-summarizer | Full-book reading via RAG, produces summary notes |
Explore | Codebase and file exploration, keyword search |
general-purpose | Multi-step research, code tasks, open-ended investigations |
Plan | Implementation planning, architecture decisions |
research-analyst | Multi-source research with synthesis and trend identification |
search-specialist | Precise information retrieval across multiple sources |
statusline-setup | Configuration and settings tasks |
The design principle is unchanged: synthesis tasks get the most capable model, pattern-matching tasks get the fast one, and rote organization inherits from the parent session.
Parallel Sessions & Nightly Sync
Cortex regularly runs 3-5 Claude Code sessions concurrently: CLI, Telegram bot, email bot, heartbeat agent, health agent. They all share the same main branch and the same working tree.
The doctrine: no in-day commits. All sessions edit files freely throughout the day. A single nightly job (cortex-vault-sync.timer, 02:00) stops every writer service, runs git add -A, commits with subject nightly sync: YYYY-MM-DD, pushes, and restarts everything.
This eliminates the commit-collision pain that plagued the previous model, where parallel sessions raced to commit and regularly mixed capture-zone files (Daily notes, MEMORY.md) with infra-zone files in the same commit. The working tree is the coordination surface — any session can see another session’s WIP immediately, without merge overhead.
Four allowed git-mutation paths are explicitly enumerated and enforced by a grep check:
vault-sync.sh— nightly autonomous commit/commit— user-invoked only, rare (pre-destructive-op or cross-machine sync)audit-infra/checkpoint.sh— push and tag, no commit/infra-pr— branch, commit on branch, GitLab MR, for infra changes that need review before landing on main
Any skill, agent, or script calling git commit|add|push|stash outside these four paths is a doctrine violation.
Scheduling
Two complementary scheduling paths serve different needs:
/at (local, heartbeat-piggyback): one-off or recurring local actions — Claude prompts, shell commands, or Telegram messages. Tasks live in .cortex/data/at/tasks.json, which the heartbeat dispatcher evaluates each tick. Supports one-off ISO datetimes and a 5-field cron subset. Example: “tomorrow at 07:15, read today’s daily note and report to Telegram.” This is the right path for anything that needs the local working tree, the Telegram bot, or local CLIs.
/schedule (Anthropic-hosted remote): cloud-shaped tasks that don’t need the local working tree — open a PR, hit an external API, post to a remote service. The remote agent can’t read today’s vault edits (which only reach git at 02:00) and can’t push the local Telegram bot.
The separation matters: virtually every “remind me tomorrow to check X” or “every Monday do Y locally” request is /at, not /schedule.
The Personal Gateway
The vault doesn’t exist in isolation. The personal gateway is a CLI that normalizes access to every external tool the vault touches: tasks, email, calendar, and contacts, across whatever specific account they happen to live in.
The gateway exists for one reason: OpenClaw struggled with multi-account routing. OpenClaw treats each external service, and each account inside that service, as its own integration with its own command shape, its own auth flow, and its own response format. Asking “what’s on my calendar today?” when “my calendar” is actually a Google personal account, an M365 work account, an iCloud family calendar, and three ICS feeds turned into an explosion of per-account commands and brittle string parsing. The model spent more time disambiguating accounts than answering the question.
The gateway flattens that. Each domain has one verb, the verb routes across all accounts, and the response is a uniform JSON shape with the source account tagged inside each item:
# Tasks (Todoist + Jira)
gateway tasks filter "today | overdue"
gateway tasks completed --since 2026-03-04 --by completion
# Calendar (Google + M365 + iCloud + arbitrary ICS feeds)
gateway calendar list --from 2026-04-30T00:00 --to 2026-05-01T00:00
# Email (Gmail + M365)
gateway email summary
# Contacts + CRM (Google + M365 + iCloud + Dex)
gateway contacts search "João"
Nine accounts are wired in today. Adding a tenth is a config entry and an OAuth round-trip, no skill changes. Removing one is the inverse. Switching from Todoist to a different task manager would mean editing the gateway’s tasks adapter, not rewriting every skill that mentions tasks. The skills only know about domains (tasks, calendar, email, contacts) and intents (list, search, add, update). The gateway is where the messy reality of OAuth scopes, token refresh, rate limits, ICS parsing, M365 vs Graph vs Outlook quirks, and Dex CRM idiosyncrasies actually lives.
There is a secrets layer underneath. Tokens live in a single secrets.json with a three-tier fallback chain (env var → file store → OS keychain), atomic-write under flock so concurrent OAuth refreshes don’t corrupt the file (an actual incident, late April 2026), and rotating snapshots every thirty minutes for recovery. None of that is visible to the skills; they call gateway tasks list and trust the result.
Beyond the gateway, the vault integrates a few thin native CLIs whose APIs don’t fit the same shape:
- Withings — body composition, weight trend, activity data
- Strava — activities via a native CLI (auto-refreshing OAuth, JSON output)
- Granola — meeting notes import (each meeting becomes a vault note with
granola_idfrontmatter, deduped on re-runs) - Book RAG — semantic search over a personal EPUB/PDF library (Qdrant + TEI on a homelab NAS)
The split is deliberate: the gateway covers the four domains where account multiplexing is the real problem; Strava and Withings each have one account and one API, and wrapping them in the gateway shape would be ceremony, not value.
A Day in the Life
Five illustrative interactions to ground the architecture. Names, projects, and Quest labels in the examples below are fictional; the surfaces, command paths, and routing logic are exactly what runs in the real system.
Free-form calendar add (Telegram, voice reply)
Just booked a 1:1 with Alex next Tuesday at 10:30 to walk through the API proposal. Add it to my calendar.
Cortex replies (voice via ElevenLabs TTS, transcribed):
“Done. 1:1 with Alex added to your work calendar for Tuesday at 10:30, 30 minutes. Personal account had a clinic appointment at 11:00, so I kept the slot tight on the work side. Ten-minute reminder set.”
Underneath: Telegram bot receives the message → auto-classifier tags it as a calendar action → gateway calendar list inspects free slots across all four calendar accounts → gateway calendar add --account m365-work lands the event → ElevenLabs TTS renders the reply, returned as an audio message.
Weekly plan consistency check (Telegram)
This week’s plan still lists [[api-redesign-proposal]] as in-progress, but I sent it for review on Monday. Why?
Cortex:
“Found the mismatch. The project note has
status: review-pendingset on Monday morning, but the outcome line in this week’s note was never updated. Closing now: marking the outcome as ‘sent for review’, moving the dependent follow-up (review-feedback triage) into next week’s queue. /closeweek would have caught it on Sunday; surfacing now instead.”
Underneath: vault-index query against the project note’s frontmatter, cross-check with the open/closed state of the outcome line in this week’s file, rewrite of the weekly file, downstream task moves via gateway tasks update.
Schedule-aware focus block prompt (Telegram)
What should I work on in the 09:00–12:00 deep block today?
Cortex:
“Three candidates, ranked by Quest support and risk:
- [[vendor-evaluation-report]] — Friday deadline, q-platform, ★ (no second runway after this morning).
- [[onboarding-doc-rewrite]] — q-team, due next week, can be split across blocks.
- Two seed notes flagged for distillation — q-research, lower stakes.
Suggest #1 in this block with a stretch on #2 if there’s time; #3 fits an evening read. Today’s morning brief framed it the same way.”
Underneath: gateway calendar list --today confirms the deep block is real, the vault index pulls active project notes ranked by Quarterly Quest weighting, cross-references this week’s outcomes from Weekly/<this-week>.md, returns the ranked list.
Retroactive vault correction from an external source (Telegram)
I forgot to push my run to Strava yesterday. Pull it now and patch yesterday’s note.
Cortex:
“Done. Strava now shows yesterday’s morning run. Patched the daily note: Health > Movement section reflects the activity, rolling 7-day cadence is updated,
training_gaptrigger condition no longer met. The morning brief that already shipped won’t be retro-edited; the gap surfaces in /closeweek.”
Underneath: strava activities list --after <yesterday> returns the freshly synced activity, vault edit on yesterday’s daily note Health section, the scorecard recomputes the rolling cadence, the health-agent state file is updated to prevent a stale training_gap trigger from firing on the next tick.
Autonomous drift nudge (Telegram, no human input)
[11:30, unprompted]
Heads up: q-platform hasn’t moved in three days. The vendor evaluation is due Friday, and Mon–Wed is fully booked with meetings, leaving Thu morning as the only window. Worth a 30-minute scope cut now, or push the deadline?
Underneath: every fourth heartbeat tick fires the /heartbeat-agent Claude session → it reads the recent Live Log, this week’s outcomes, and calendar density for the next four days → notices the q-platform stall against an approaching deadline → composes the nudge, routes through proactivity_governance (one-push-per-day budget, defer-after-user gate) and then through the outbox (body-hash dedup) before reaching Telegram.
The first four examples are user-initiated. The fifth is autonomous and fires only when the heartbeat-agent’s reasoning surfaces a real shift, never on every tick. The architecture from earlier sections explains how each one runs; this is what they look like in practice.
The Memory System
Claude Code sessions are stateless by default. Cortex works around this with a layered memory system:
CLAUDE.md(~100 lines, always loaded) — Governance, platform conventions, key rules.claude/rules/(loaded by file pattern or always) — Domain-specific conventions (gateway tasks, language, HITL workflows, prioritization)SKILL.md(loaded per invocation) — Multi-phase workflow for that skillMEMORY.md(always loaded) — Durable learnings: stable patterns, debugging insights, session history
MEMORY.md now carries close to 90 topic entries, each pointing to a separate file. The compounding effect is real: debugging insights from April prevent repeating the same mistakes in October. Behavioral observations (morning focus blocks hold longer than afternoon ones, commit-ordering matters in parallel sessions) improve future decisions.
SQLite Vault Index
Obsidian’s search is good for content, but weak for structural queries like “which notes have no backlinks?” or “show me all seed notes older than 30 days.” Cortex maintains a SQLite index with:
- Note metadata: type, status, folder, tags, word count, dates
- Link graph: forward links, backlinks, broken links
- Entity index: people and companies by filename and title, for sub-second lookup before asking “who is X?”
- Embeddings: 384-dimensional vectors from
all-MiniLM-L6-v2for semantic search
Relational queries (orphans, broken links, entity lookup) run 14x faster than the equivalent grep pipeline, with higher accuracy. Simple text searches still favor grep by 3-10x due to Python startup overhead. The index rebuilds nightly via cortex-reindex.timer.
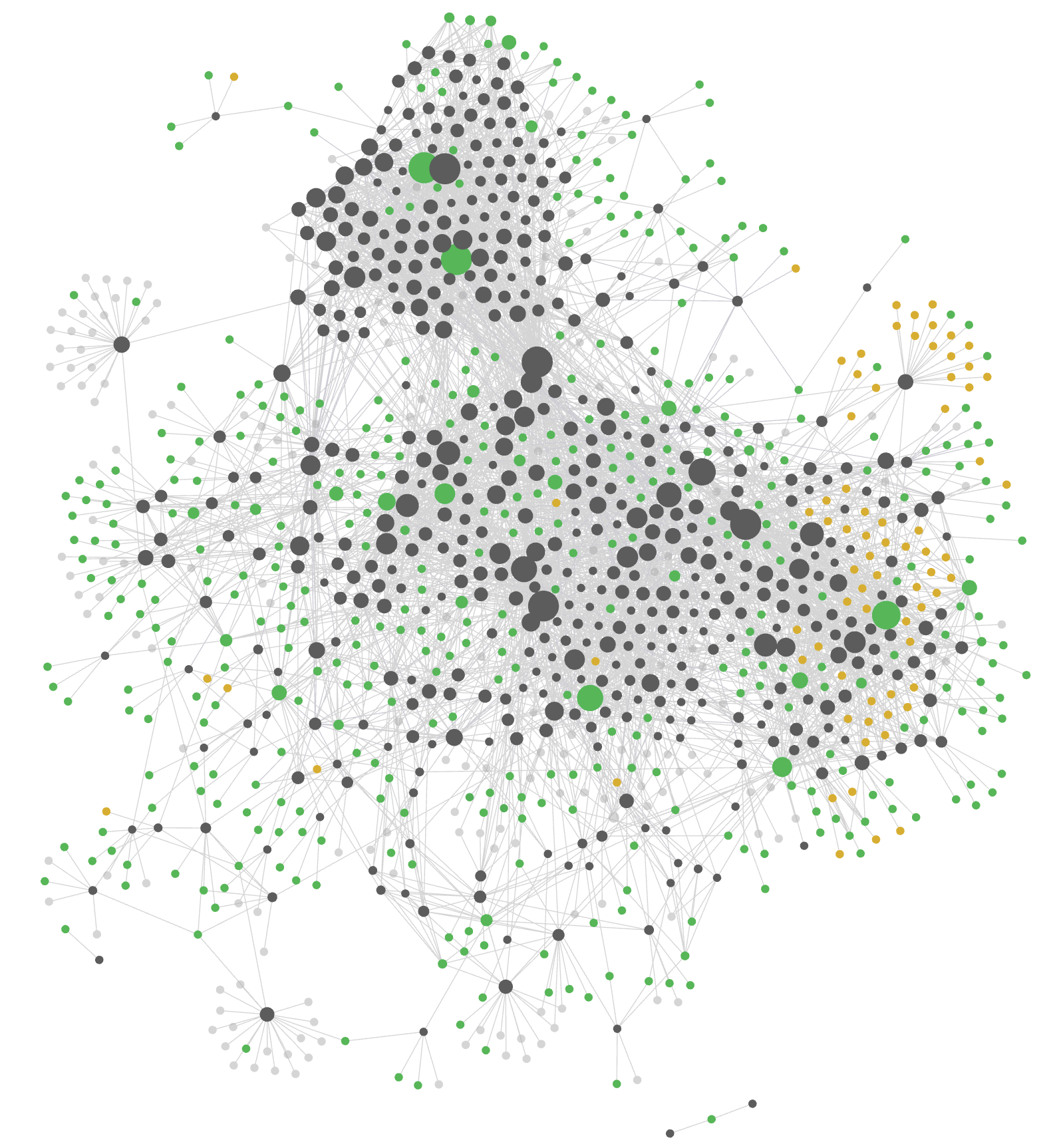
Figure 5 — Cortex vault as a force-directed graph after a year of capture-and-link. Each node is a note; each edge a wikilink between notes. Node size scales with backlink count. The brain-shaped silhouette emerges from the link structure alone, no manual layout.
What I’ve Learned
Governance beats flexibility. The Inbox-first rule seemed restrictive at first, but it’s the single most important pattern. Without it, notes proliferate in random locations and the vault structure degrades within weeks.
The commit model matters more than you expect. Three months of parallel-session pain — mixed-provenance commits, session races, MEMORY.md edited by five sessions on the same day — dissolved with one decision: no in-day commits. All edits live in the working tree; one scheduled job owns the commit.
Capture friction is the enemy. The Telegram auto-capture classifier was the highest-ROI addition in the last two months. The barrier to “just send a voice note” is much lower than “open Obsidian and create a note.” The classifier handles routing; the human provides the raw signal.
Autonomous agents need dedup by design. The heartbeat and health agent both fire alerts only when trigger states change, not on every tick. Without this, a weight_above_goal condition would generate an alert every hour. Dedup-by-date is the minimum viable pattern for any autonomous signal.
Skills should be phases, not monoliths. Breaking workflows into numbered phases with explicit parallel tool calls makes them faster and more debuggable. /closeday has 11 phases; each can be reasoned about independently. A broken phase fails loudly instead of silently corrupting the whole synthesis.
Meta-work expands to fill available time. Building the system is satisfying. Using it to get actual work done is the point. The system now flags this itself, with stalled-outcome nudges that reach the morning brief whenever a Quest goes quiet for several days.
The best system is the one you grew yourself. The biggest mistake would be to copy Cortex, or any other project, and expect it to work. The value accumulates precisely because each skill, each rule, each integration was added in response to a real friction point in a real week. Nobody else has your calendar, your Todoist structure, your reading list, your sprint planning rhythms. A second brain built to fit someone else’s life is a second brain you will stop using. Start small, feel the friction, add the layer that resolves it.
Cortex 2.0: The Goblet Refactor
By late April, Cortex had grown to 56 skills, 4 submodules, 30+ Python entry points, 37 shell scripts, 6 systemd timers, and 8 services. From a distance it looked sprawling, with five independent YAML parsers, thirteen ad-hoc HTTP clients, ten different env-loading patterns, twelve shell wrappers around single Python invocations, and a cortex_lib shared library that was being imported in only ten places out of dozens of opportunities.
The natural reaction was to consolidate everything into a single binary, the way NanoClaw collapsed OpenClaw. That would be the wrong move, and the reason matters.
NanoClaw is one application with channel adapters. It has one runtime agency: receive a message, route to the model, reply. Cortex is a platform that hosts many applications with fundamentally different runtime agencies:
- Interactive Claude Code sessions —
/today,/closeday,/sweep,/week,/quarter. These need the SDK loop, multi-turn reasoning, and the user as a gating peer. - Autonomous timers — heartbeat dispatcher, vault-sync, secrets-backup, reindex, preflight, health-agent. These run unattended on systemd schedules.
- Always-on daemons — Telegram bot, email bot. Long-lived processes with their own asyncio loops.
- Spawned agents — heartbeat-agent, health-agent, scheduled-task. Each is a fresh Claude Code session inside a transient systemd unit, specifically because they need to outlive the parent oneshot.
These don’t merge into one process without inventing the multi-process model right back. NanoClaw can be one binary because NanoClaw doesn’t need a 02:00 vault snapshot job, an autonomous body-fat-drift trigger, or 50 user-invokable interactive workflows.
There’s also a Claude-Code-specific reason. The folder shape .claude/skills/<name>/SKILL.md + scripts/ is the API:
- Claude Code auto-discovers skills by walking the directory and parsing frontmatter. Per-skill
description,argument-hint,disable-model-invocationflags drive routing. - The Telegram and email bots auto-register the same way. No bot-specific handlers.
- Progressive disclosure: only the SKILL.md you invoke lands in Claude’s context. A single binary would have to reinvent that registry to keep context costs sane.
- Per-skill
disable-model-invocation: true(used on/commit,/infra-pr,/release) is enforced by Claude Code’s loader, not by your code. Folding those into one binary moves enforcement to your code.
In short: collapsing the 56 skills into one CLI breaks the runtime contract with the harness, the bots, and the audit tooling. The “sprawl” of 56 folders is paying for something real.
The metaphor
A goblet that looks fragmented because of its facets is not the same as a goblet that’s been dropped on the floor.
Cortex’s surface (the 56 skill folders) is the first kind, faceted on purpose because the harness, bots, and audits all read the facets directly. The underbelly (5 YAML parsers, 13 HTTP clients, 10 env loaders, 12 shell wrappers) is the second kind, actual fragmentation. The right move is to glue the underbelly and leave the facets.
That insight, written down in late April, drove what landed on May 2 as Cortex 2.0: the working tree split into two repos.
| Repo | Contents | Purpose |
|---|---|---|
cortex-vault | The Obsidian vault content (Daily, Weekly, PARA folders, MOCs, daily notes) | Strictly private. The actual life data. |
cortex-infra | Skills, rules, agents, scripts, systemd units, schemas, shared libraries | Intended to be shareable. The harness anyone could run against their own vault. |
Both repos share a working tree on disk; the split is a logical separation that makes it possible to publish the harness without the data. A four-layer PII scrub plan was drafted (extend .env.example with owner scalars; introduce .cortex/config/owner.toml for structured config like Todoist GUIDs and calendar account IDs; narrative scrub of rules and SKILLs with anonymized examples like Acme Analog; gitignore personal memory files and ship .example scaffolds). Execution was deferred pending a publishability decision, but the architectural split itself stands on its own merit.
The underbelly consolidation rolls in opportunistically as skills get touched. Three independent moves, each high-ROI on its own:
- Grow
cortex_libinto the actual platform — addfrontmatter,daily_note,http,gateway_clientmodules. Replace 5 YAML parsers with one. Replace 13 HTTP clients with one. The migration target is afrom cortex_libimport count rising from 10 to 30+. - One
cortexCLI replaces 12 shell wrappers —gateway.sh → cortex gateway tasks list ...,book-rag.sh → cortex book-rag search ..., etc. Skills’scripts/directories shrink as wrappers retire. The folder API stays exactly the same. - Retire launcher shell scripts — once the CLI lands,
run-today.sh,run-checkin.sh, and friends become trivialcortex <subcmd>invocations or move intocortex_libas importable functions. The systemd unit ExecStart lines update to callcortexdirectly.
Cortex 2.0 is what happens when a system gets big enough to have an underbelly worth examining, but small enough that you can still tell the difference between sprawl and surface area. A second brain that grows for a year will face this question. The cleanest answer is rarely “consolidate everything”; it’s “find what’s actually fragmented and glue only that.”
When Not to Build This
The critique writes itself, and it’s worth landing honestly.
This is not a consumer-friendly tool. Cortex is roughly 56 skills, dozens of Python entry points, six systemd timers, a SQLite index, a NATS JetStream broker, two long-lived bots, and a working tree shared across five concurrent Claude Code sessions. Deploying it requires comfort with Linux user units, OAuth flows for half a dozen services, Python packaging via uv, and enough Claude Code documentation to understand the difference between a skill, an agent, and a hook. If debugging systemd unit files is not already part of your week, this is not the system you want to maintain.
You trade note maintenance for software maintenance. Cortex removes the burden of manually filing notes, pruning seeds, and writing weekly synthesis. It does not remove the burden of running the system. By late April the underbelly had grown five YAML parsers, thirteen ad-hoc HTTP clients, ten env-loading patterns, and twelve shell wrappers all needing deduplication. The Cortex 2.0 refactor was not optional, and a system at this scale needs periodic refactoring in the same way production code does.
It will not port to your life. Skills are wired to my Todoist project IDs, my Withings goals, my Strava cadence, my calendar accounts, my Quarterly Quest labels, and my daily rhythm. Lifting the harness onto a different life is not a copy-paste; it is a rewrite of every skill that touches external state. The publishable shape of the harness exists (Cortex 2.0 split vault from infra precisely so the infra could be open-sourced), but the value lives in the wiring, and the wiring has to be yours.
It will feel rigid if you work fluidly. The Inbox-first rule is non-negotiable. Daily, weekly, and quarterly closes run on a fixed schedule. Every note carries required frontmatter; every external integration goes through one gateway. If your work is improvisational, exploratory, or visual-first, this discipline will feel like overhead. Governance buys consistency at the cost of friction, and the friction is always paid by the human at capture time.
What Cortex is good at: making a structured-thinker’s already-structured life machine-readable, surfacing patterns across long timescales, and turning the boring work of weekly review into something that runs while you sleep. What it is not: a productivity hack you can adopt over a weekend.
Architecture Diagram
Four columns, left to right: how messages enter (CLI, Telegram, email), what reasons over them (Claude Code with skills, agents, memory), what gets read and written (the Obsidian vault and its index), and the integrations and automations that keep the rest of the world wired in. The arrows show the runtime path of a single interaction: a message lands on an interface, Claude Code picks up the relevant skill, the vault is read or updated, and integrations fan out to Todoist, Gmail, Strava, or whatever the skill needs. Everything in the right-hand Automation column runs on its own systemd timer, with no human in the loop.
Source Code
Cortex is a private repository (it contains my actual life data), but the patterns are transferable. The key ingredients are:
- An Obsidian vault with consistent structure (PARA or similar)
- Claude Code with
.claude/configuration (skills, agents, rules, memory) - A gateway CLI wrapping your productivity tools
- A SQLite index for structural queries
- Git for versioning, with a nightly-sync model if you run parallel sessions
- A lightweight message bus (NATS or equivalent) if you want autonomous domain agents communicating
The infrastructure is roughly 4,000 lines of skill definitions, 2,000 lines of Python, and 500 lines of shell. The vault has 350+ notes across all categories.
The Telegram bot builds on claude-code-telegram by Richard Tackett, with contributions back upstream (voice transcription improvements, PR pending). The personal gateway CLI, which handles Todoist, Gmail, M365, Google Calendar, iCloud, and Dex CRM in a unified interface, will be open-sourced at a later stage. Depending on how useful the full system proves to others, the Cortex skill and agent layer may follow.
If you’re interested in building something similar, the Claude Code documentation covers skills, agents, and the memory system. The real work isn’t in the code — it’s in defining the governance rules and workflows that match how you actually think.